
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPOtimização ABAP para SAP HANA: Estratégias de Code Pushdown e SQL Nativo
- Creado 01/03/2024
- Modificado 01/03/2024
- 62 Vistas
0
Cargando...
Paradigma Code-to-Data:
Olá a todos! Comecei a aprender ABAP com o SAP HANA e, no processo de aprendizagem, aprendi técnicas de Code Pushdown. Code pushdown é simplesmente um mecanismo que empurra o código para a camada do banco de dados e obtém o conjunto de resultados necessário em vez de obter todos os dados na camada de aplicação e escrever o código na camada de aplicação para obter a saída necessária. Este conceito não é novo para mim, eu o conheci quando comecei a trabalhar em aplicações web utilizando tecnologias como Java e MySQL há 6 anos.
Percebo que Code pushdown não é nada novo, simplesmente é "novo" para vários desenvolvedores de ABAP. Portanto, gostaria de compartilhar minha exploração sobre isso.
Estilo de Codificação ABAP Tradicional : No antigo estilo de codificação ABAP, é prática padrão limitar o número de consultas ao banco de dados transferindo a maior quantidade de dados possível para o servidor de aplicação e depois realizando as operações necessárias para fornecer a saída necessária, embora recuperar uma grande quantidade de dados de um banco de dados leve tempo.
Na linguagem de programação ABAP/4, são utilizados 2 estilos de SQL.
Open SQL permite acessar tabelas de banco de dados declaradas no Dicionário ABAP, independentemente da plataforma de banco de dados que você esteja usando no Sistema R/3.
SQL Nativo permite usar declarações SQL específicas do banco de dados em um programa ABAP, ou seja, declarações SQL dependentes do banco de dados. Você pode usar tabelas de banco de dados que não são gerenciadas pelo Dicionário ABAP e integrar dados que não fazem parte do Sistema R/3.
A sintaxe para usar SQL Nativo.
EXEC SQL [EXECUTING form].
SQL específico do banco de dados.
FINEXEC.
Atualmente, a SAP utiliza o HANA como seu banco de dados nativo para armazenar dados no S/4 HANA.
Hana não é apenas um banco de dados, mas também fornece os seguintes benefícios poderosos.
Armazenamento de Dados por Linhas e Colunas,
Compressão de Dados,
suportando ambos: padrões OLTP e OLAP em uma única aplicação,
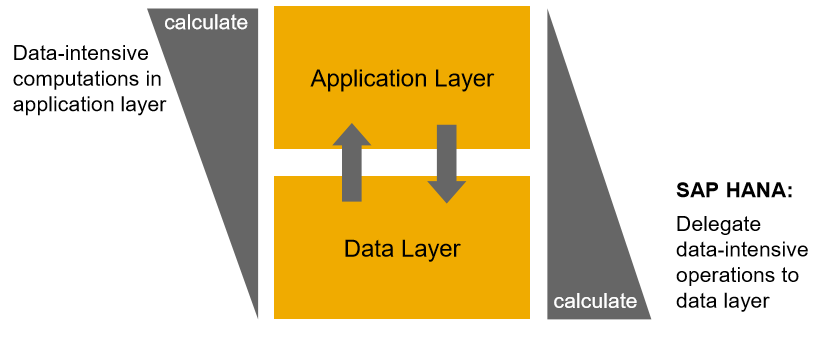
O conceito de computação em memória do Banco de Dados Hana produz a capacidade de evitar o movimento desnecessário de grandes volumes de dados e realizar cálculos intensivos em dados dentro do banco de dados. Uma vez que a operação intensiva em dados é realizada, apenas o resultado é transferido e utilizado em seu programa ABAP.
Este novo paradigma de programação é chamado de código para dados ou Code Pushdown.
Abaixo está a imagem de referência.
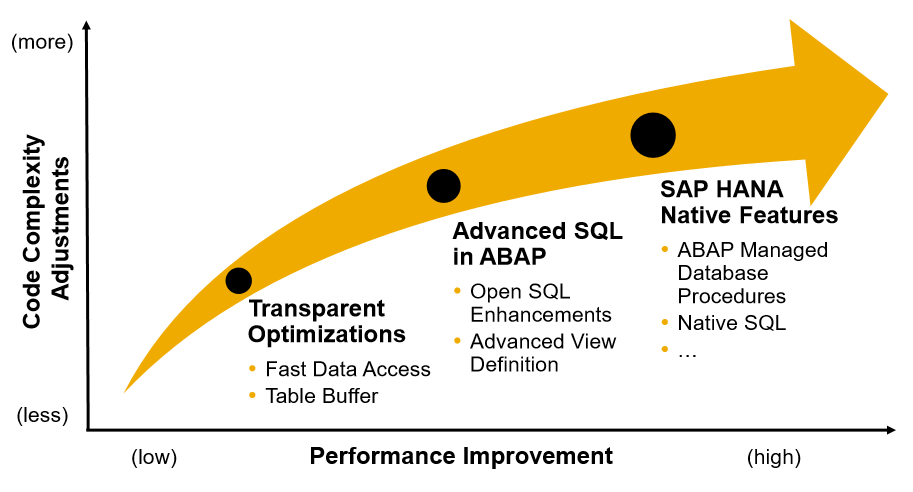
Uma aplicação ABAP pode ser otimizada para o SAP HANA em 3 níveis.
1) Otimizações Transparentes: Acesso rápido aos dados,
2) Melhorias no Buffer de Tabelas. SQL Avançado em ABAP: Melhorias no Open SQL, Vistas CDS
3) Características Nativas do SAP HANA: AMDP, SQL Nativo.
Para apoiar os desenvolvedores de ABAP que seguem o paradigma Code-to-Data, a SAP desenvolveu uma abordagem de baixo para cima com um produto, ABAP 7.4 com o pacote de suporte principal, o suporte SP2
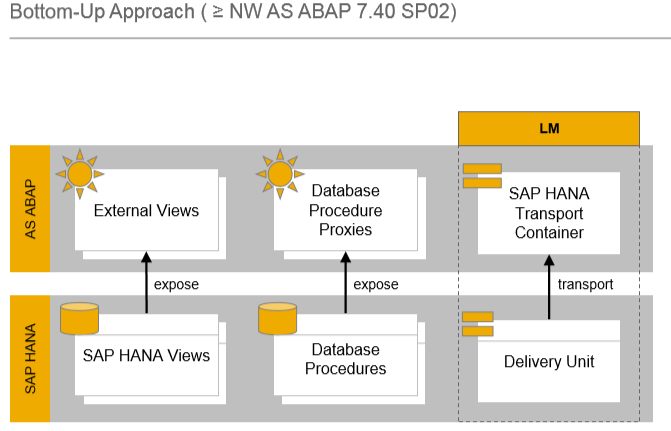
Abordagem de Baixo para Cima: este é um bom conceito na teoria, mas tem algumas desvantagens. Um dos principais problemas é com o Sistema de Gerenciamento do Ciclo de Vida do HANA.
As visualizações do HANA e os procedimentos de banco de dados do HANA são gerenciados pelo Sistema de Gerenciamento do Ciclo de Vida do HANA. Estes residem em uma unidade de entrega que precisa ser transportada. E por outro lado, você tem as visualizações externas e os proxies dos procedimentos de banco de dados.
Ao usar a nova instrução de linguagem ABAP, podemos chamar o procedimento de banco de dados.
Chamar PROCEDIMENTO de banco de dados .
Se algo mudar aqui ao nível do banco de dados, o dicionário de dados não saberá. Precisamos sincronizar manualmente os objetos proxy para as visualizações e também deve transportar a unidade de entrega. Você pode fazer isso dentro do contêiner de transporte do SAP HANA.
Olá a todos! Comecei a aprender ABAP com o SAP HANA e, no processo de aprendizagem, aprendi técnicas de Code Pushdown. Code pushdown é simplesmente um mecanismo que empurra o código para a camada do banco de dados e obtém o conjunto de resultados necessário em vez de obter todos os dados na camada de aplicação e escrever o código na camada de aplicação para obter a saída necessária. Este conceito não é novo para mim, eu o conheci quando comecei a trabalhar em aplicações web utilizando tecnologias como Java e MySQL há 6 anos.
Percebo que Code pushdown não é nada novo, simplesmente é "novo" para vários desenvolvedores de ABAP. Portanto, gostaria de compartilhar minha exploração sobre isso.
Estilo de Codificação ABAP Tradicional : No antigo estilo de codificação ABAP, é prática padrão limitar o número de consultas ao banco de dados transferindo a maior quantidade de dados possível para o servidor de aplicação e depois realizando as operações necessárias para fornecer a saída necessária, embora recuperar uma grande quantidade de dados de um banco de dados leve tempo.
Na linguagem de programação ABAP/4, são utilizados 2 estilos de SQL.
Open SQL permite acessar tabelas de banco de dados declaradas no Dicionário ABAP, independentemente da plataforma de banco de dados que você esteja usando no Sistema R/3.
SQL Nativo permite usar declarações SQL específicas do banco de dados em um programa ABAP, ou seja, declarações SQL dependentes do banco de dados. Você pode usar tabelas de banco de dados que não são gerenciadas pelo Dicionário ABAP e integrar dados que não fazem parte do Sistema R/3.
A sintaxe para usar SQL Nativo.
EXEC SQL [EXECUTING form].
SQL específico do banco de dados.
FINEXEC.
Atualmente, a SAP utiliza o HANA como seu banco de dados nativo para armazenar dados no S/4 HANA.
Hana não é apenas um banco de dados, mas também fornece os seguintes benefícios poderosos.
Armazenamento de Dados por Linhas e Colunas,
Compressão de Dados,
suportando ambos: padrões OLTP e OLAP em uma única aplicação,
O conceito de computação em memória do Banco de Dados Hana produz a capacidade de evitar o movimento desnecessário de grandes volumes de dados e realizar cálculos intensivos em dados dentro do banco de dados. Uma vez que a operação intensiva em dados é realizada, apenas o resultado é transferido e utilizado em seu programa ABAP.
Este novo paradigma de programação é chamado de código para dados ou Code Pushdown.
Abaixo está a imagem de referência.
Uma aplicação ABAP pode ser otimizada para o SAP HANA em 3 níveis.
1) Otimizações Transparentes: Acesso rápido aos dados,
2) Melhorias no Buffer de Tabelas. SQL Avançado em ABAP: Melhorias no Open SQL, Vistas CDS
3) Características Nativas do SAP HANA: AMDP, SQL Nativo.
Para apoiar os desenvolvedores de ABAP que seguem o paradigma Code-to-Data, a SAP desenvolveu uma abordagem de baixo para cima com um produto, ABAP 7.4 com o pacote de suporte principal, o suporte SP2
Abordagem de Baixo para Cima: este é um bom conceito na teoria, mas tem algumas desvantagens. Um dos principais problemas é com o Sistema de Gerenciamento do Ciclo de Vida do HANA.
As visualizações do HANA e os procedimentos de banco de dados do HANA são gerenciados pelo Sistema de Gerenciamento do Ciclo de Vida do HANA. Estes residem em uma unidade de entrega que precisa ser transportada. E por outro lado, você tem as visualizações externas e os proxies dos procedimentos de banco de dados.
Ao usar a nova instrução de linguagem ABAP, podemos chamar o procedimento de banco de dados.
Chamar PROCEDIMENTO de banco de dados .
Se algo mudar aqui ao nível do banco de dados, o dicionário de dados não saberá. Precisamos sincronizar manualmente os objetos proxy para as visualizações e também deve transportar a unidade de entrega. Você pode fazer isso dentro do contêiner de transporte do SAP HANA.
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2025 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?