
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPOptimización ABAP para SAP HANA: Estrategias de Code Pushdown y SQL Nativo
- Creado 01/03/2024
- Modificado 01/03/2024
- 187 Vistas
0
Cargando...
Paradigma Code-to-Data:
¡Hola a todos! Comencé a aprender ABAP con SAP HANA y en el proceso de aprendizaje, aprendí técnicas de Code Pushdown. Code pushdown es simplemente un mecanismo que empuja el código hacia la capa de la base de datos y obtiene el conjunto de resultados requerido en lugar de obtener todos los datos en la capa de la aplicación y escribir el código en la capa de la aplicación para obtener la salida requerida. Este concepto no es nuevo para mí, lo conocí cuando comencé a trabajar en aplicaciones web utilizando tecnologías como Java y MySQL hace 6 años.
Percibo que Code pushdown no es nada nuevo, simplemente es "nuevo" para varios desarrolladores de ABAP. Por lo tanto, me gustaría compartir mi exploración sobre esto.
Estilo de Codificación ABAP Tradicional : En el antiguo estilo de codificación ABAP, es una práctica estándar limitar el número de consultas a la base de datos transfiriendo la mayor cantidad de datos posible al servidor de aplicaciones y luego realizando las operaciones necesarias para proporcionar la salida requerida, aunque recuperar una gran cantidad de datos de una base de datos lleva tiempo.
En el lenguaje de programación ABAP/4, se utilizan 2 estilos de SQL.
Open SQL te permite acceder a tablas de base de datos declaradas en el Diccionario ABAP sin importar la plataforma de base de datos que estés usando en el Sistema R/3.
SQL Nativo te permite utilizar declaraciones SQL específicas de la base de datos en un programa ABAP, lo que significa declaraciones SQL dependientes de la base de datos. Puedes utilizar tablas de base de datos que no están administradas por el Diccionario ABAP e integrar datos que no forman parte del Sistema R/3.
La sintaxis para usar SQL Nativo.
EXEC SQL [EJECUTANDO formulario].
SQL específico de la base de datos.
FINEXEC.
Actualmente SAP utiliza HANA como su base de datos nativa para almacenar datos en S/4 HANA.
Hana no es solo una base de datos, sino que también proporciona los siguientes beneficios poderosos.
Almacenamiento de Datos por Filas y Columnas,
Compresión de Datos,
soportando ambos: patrones OLTP y OLAP en una sola aplicación,
El concepto de cómputo en memoria de la Base de Datos Hana produce la capacidad de evitar el movimiento innecesario de grandes volúmenes de datos y realizar cálculos intensivos en datos dentro de la base de datos. Una vez que se realiza la operación intensiva en datos, solo se transfiere el resultado y se utiliza en tu programa ABAP.
Este nuevo paradigma de programación se llama código a datos o Code Pushdown.
A continuación se muestra la imagen de referencia.
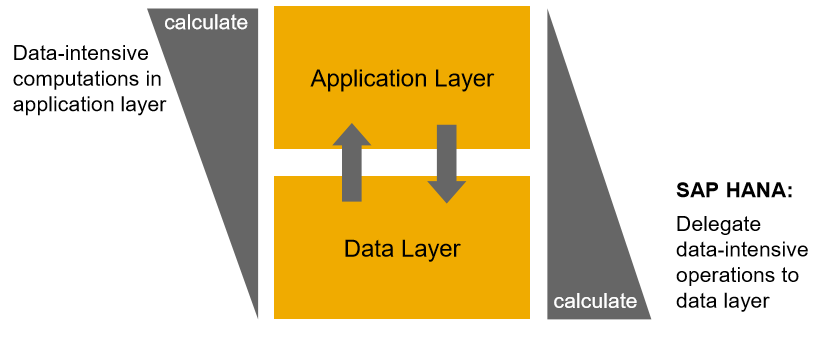
Una aplicación ABAP puede optimizarse para SAP HANA en 3 niveles.
1) Optimizaciones Transparentes: Acceso rápido a datos,
2) Mejoras en el Búfer de Tablas. SQL Avanzado en ABAP: Mejoras en Open SQL, Vistas CDS
3) Características Nativas de SAP HANA: AMDP, SQL Nativo.
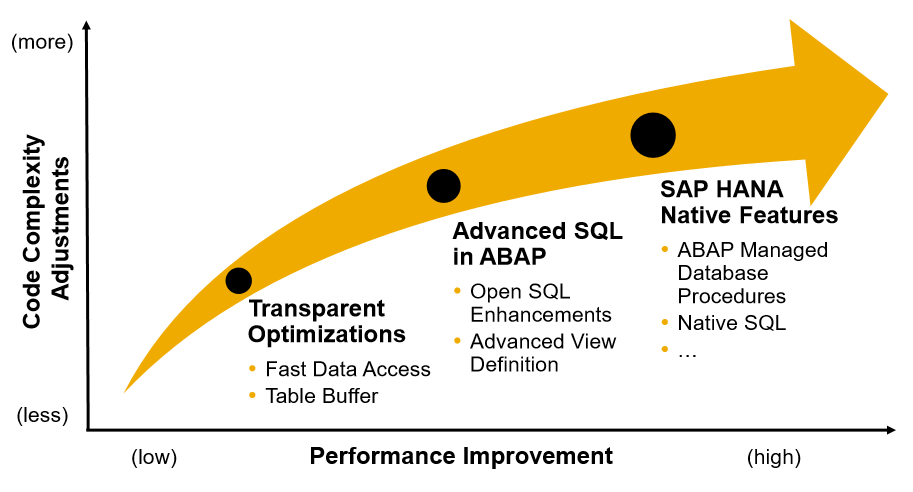
Para apoyar a los desarrolladores de ABAP que siguen el paradigma Code-to-Data, SAP ha desarrollado un enfoque de abajo hacia arriba con un producto, ABAP 7.4 con el paquete de soporte principal, el soporte SP2
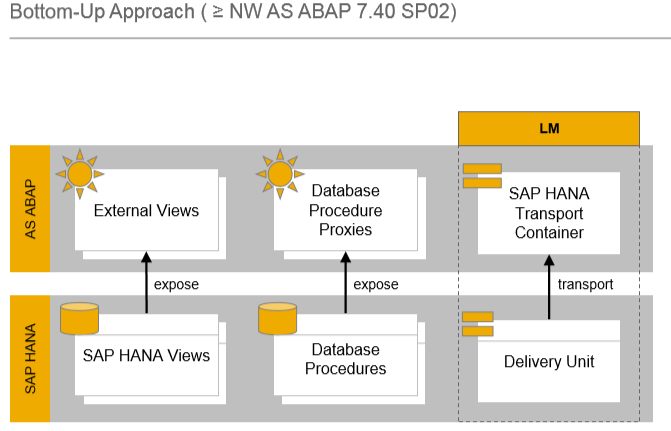
Enfoque de Abajo hacia Arriba: este es un buen concepto en teoría, pero tiene algunas desventajas. Uno de los problemas principales es con el Sistema de Gestión del Ciclo de Vida de HANA.
Las vistas de HANA y los procedimientos de base de datos de HANA son gestionados por el Sistema de Gestión del Ciclo de Vida de HANA. Estos residen en una unidad de entrega que necesita ser transportada. Y por otro lado, tienes las vistas externas y los proxies de procedimientos de base de datos.
Al utilizar la nueva instrucción de lenguaje ABAP, podemos llamar al procedimiento de base de datos.
Llamar a PROCEDIMIENTO de base de datos .
Si algo cambia aquí a nivel de base de datos, el diccionario de datos no lo sabe. Necesitamos sincronizar manualmente los objetos proxy para las vistas y también debes transportar la unidad de entrega. Puedes hacerlo dentro del contenedor de transporte de SAP HANA,
¡Hola a todos! Comencé a aprender ABAP con SAP HANA y en el proceso de aprendizaje, aprendí técnicas de Code Pushdown. Code pushdown es simplemente un mecanismo que empuja el código hacia la capa de la base de datos y obtiene el conjunto de resultados requerido en lugar de obtener todos los datos en la capa de la aplicación y escribir el código en la capa de la aplicación para obtener la salida requerida. Este concepto no es nuevo para mí, lo conocí cuando comencé a trabajar en aplicaciones web utilizando tecnologías como Java y MySQL hace 6 años.
Percibo que Code pushdown no es nada nuevo, simplemente es "nuevo" para varios desarrolladores de ABAP. Por lo tanto, me gustaría compartir mi exploración sobre esto.
Estilo de Codificación ABAP Tradicional : En el antiguo estilo de codificación ABAP, es una práctica estándar limitar el número de consultas a la base de datos transfiriendo la mayor cantidad de datos posible al servidor de aplicaciones y luego realizando las operaciones necesarias para proporcionar la salida requerida, aunque recuperar una gran cantidad de datos de una base de datos lleva tiempo.
En el lenguaje de programación ABAP/4, se utilizan 2 estilos de SQL.
Open SQL te permite acceder a tablas de base de datos declaradas en el Diccionario ABAP sin importar la plataforma de base de datos que estés usando en el Sistema R/3.
SQL Nativo te permite utilizar declaraciones SQL específicas de la base de datos en un programa ABAP, lo que significa declaraciones SQL dependientes de la base de datos. Puedes utilizar tablas de base de datos que no están administradas por el Diccionario ABAP e integrar datos que no forman parte del Sistema R/3.
La sintaxis para usar SQL Nativo.
EXEC SQL [EJECUTANDO formulario].
SQL específico de la base de datos.
FINEXEC.
Actualmente SAP utiliza HANA como su base de datos nativa para almacenar datos en S/4 HANA.
Hana no es solo una base de datos, sino que también proporciona los siguientes beneficios poderosos.
Almacenamiento de Datos por Filas y Columnas,
Compresión de Datos,
soportando ambos: patrones OLTP y OLAP en una sola aplicación,
El concepto de cómputo en memoria de la Base de Datos Hana produce la capacidad de evitar el movimiento innecesario de grandes volúmenes de datos y realizar cálculos intensivos en datos dentro de la base de datos. Una vez que se realiza la operación intensiva en datos, solo se transfiere el resultado y se utiliza en tu programa ABAP.
Este nuevo paradigma de programación se llama código a datos o Code Pushdown.
A continuación se muestra la imagen de referencia.
Una aplicación ABAP puede optimizarse para SAP HANA en 3 niveles.
1) Optimizaciones Transparentes: Acceso rápido a datos,
2) Mejoras en el Búfer de Tablas. SQL Avanzado en ABAP: Mejoras en Open SQL, Vistas CDS
3) Características Nativas de SAP HANA: AMDP, SQL Nativo.
Para apoyar a los desarrolladores de ABAP que siguen el paradigma Code-to-Data, SAP ha desarrollado un enfoque de abajo hacia arriba con un producto, ABAP 7.4 con el paquete de soporte principal, el soporte SP2
Enfoque de Abajo hacia Arriba: este es un buen concepto en teoría, pero tiene algunas desventajas. Uno de los problemas principales es con el Sistema de Gestión del Ciclo de Vida de HANA.
Las vistas de HANA y los procedimientos de base de datos de HANA son gestionados por el Sistema de Gestión del Ciclo de Vida de HANA. Estos residen en una unidad de entrega que necesita ser transportada. Y por otro lado, tienes las vistas externas y los proxies de procedimientos de base de datos.
Al utilizar la nueva instrucción de lenguaje ABAP, podemos llamar al procedimiento de base de datos.
Llamar a PROCEDIMIENTO de base de datos .
Si algo cambia aquí a nivel de base de datos, el diccionario de datos no lo sabe. Necesitamos sincronizar manualmente los objetos proxy para las vistas y también debes transportar la unidad de entrega. Puedes hacerlo dentro del contenedor de transporte de SAP HANA,
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2025 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?