
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPIntegrating Machine Learning with SAP BW/4HANA for Enhanced Data-driven Insights
- Creado 01/03/2024
- Modificado 01/03/2024
- 272 Vistas
0
Cargando...
Machine Learning in SAP HANA is a great thing. With the two embedded Machine Learning libraries (
PAL
and
APL
) to choose from, which support all the core Machine Learning tasks, you’re more than well equipped to build data driven, intelligent solutions in SAP HANA.
Now, Machine Learning in SAP HANA becomes even better, when being coupled with an application. Only then, data driven insights can be integrated and leveraged where they are most needed - as part of business processes. While SAP S/4HANA offers a large selection of predefined intelligent scenarios and provides a standard tool kit for custom Machine Learning enhancements ( LINK ), SAP BW/4HANA customers sometimes struggle with starting Machine Learning initiatives on top of their existing Data Warehouse.
My colleague tobiaswohkittel and I joined forces to help overcome these struggles. With this blog post, we intend to provide specific guidance with regards to how Machine Learning can be easily integrated with core SAP BW artifacts, leveraging all the standard tools provided with SAP BW/4HANA. Integration will be the focus of this article and we’ll keep the Machine Learning part very simple and based on default values.
You can find all our development artifacts, including the sample data, our Jupyter notebook and the ABAP code snippets in our samples GitHub repository . It is based on an SAP BW/4 2.0, which runs on ABAP Foundation 7.53 and SAP HANA SP05, and our Python API version 2.11.22010700.
Let’s back up for a moment and see, what we are about to do specifically.
Machine Learning has 2 core processes: Training a model and applying a model to receive forecasts / predictions (often referred to as Inference ). We’ll bring both to live here. In doing so, our goal is to stay as close to SAP BW standards as possible with minimum custom coding. SAP BW has several great modeling objects and tools, that we will utilize for that:
The Advanced DataStore Object (aDSO) is the standard data-holding object, comparable to a database table. A Transformation defines rules to be executed against this data while moving it between two aDSOs. A Data Transfer Process (DTP) helps us trigger these Transformations. And lastly, there is ABAP as our native script language, and specifically ABAP Managed Database Procedures (AMDPs) , that build the bridge between ABAP and SAP HANA, by wrapping SQLScript in ABAP code. You will find all of them in the below overview of our target architecture.
Now, if you have a bit of SAP BW background, this scheme might look odd to you. In typical Data Warehousing scenarios and ETL workloads, a Transformation would only apply minor changes to the data, by performing calculations, string operations, conversions, and the likes. Here, input and output of the Transformation seem to be completely disconnected, but in the end, Machine Learning is in fact just one very complex transformation of data and the good news is: it works great and helps us stay within standard tooling.
With this plan all laid out, we are ready to take a look at the actual system now.
For this demo, we will use some made up salary data and predict the corresponding job level, an employee should be associated with, based on some demographic and employment data. The picture below shows an extract of this data.
From here on, we will leverage the tight integration between SAP HANA and SAP BW/4HANA, that allows our Data Scientist to work with native features in SAP HANA as well as Python, while our SAP BW expert keeps maintaining all structures with standard SAP BW tools.
To mimic a standard reporting scenario, the Data Scientist is only given access to a query based on the training data instead of the raw data table. This query automatically translates into an SAP HANA Calculation View that can be accessed using the Python client for SAP HANA Machine Learning. So, experimenting and working with the data from SAP BW feels natural to the Data Scientist. Since our target variable “
Now, Machine Learning in SAP HANA becomes even better, when being coupled with an application. Only then, data driven insights can be integrated and leveraged where they are most needed - as part of business processes. While SAP S/4HANA offers a large selection of predefined intelligent scenarios and provides a standard tool kit for custom Machine Learning enhancements ( LINK ), SAP BW/4HANA customers sometimes struggle with starting Machine Learning initiatives on top of their existing Data Warehouse.
My colleague tobiaswohkittel and I joined forces to help overcome these struggles. With this blog post, we intend to provide specific guidance with regards to how Machine Learning can be easily integrated with core SAP BW artifacts, leveraging all the standard tools provided with SAP BW/4HANA. Integration will be the focus of this article and we’ll keep the Machine Learning part very simple and based on default values.
You can find all our development artifacts, including the sample data, our Jupyter notebook and the ABAP code snippets in our samples GitHub repository . It is based on an SAP BW/4 2.0, which runs on ABAP Foundation 7.53 and SAP HANA SP05, and our Python API version 2.11.22010700.
The Plan
Let’s back up for a moment and see, what we are about to do specifically.
Machine Learning has 2 core processes: Training a model and applying a model to receive forecasts / predictions (often referred to as Inference ). We’ll bring both to live here. In doing so, our goal is to stay as close to SAP BW standards as possible with minimum custom coding. SAP BW has several great modeling objects and tools, that we will utilize for that:
The Advanced DataStore Object (aDSO) is the standard data-holding object, comparable to a database table. A Transformation defines rules to be executed against this data while moving it between two aDSOs. A Data Transfer Process (DTP) helps us trigger these Transformations. And lastly, there is ABAP as our native script language, and specifically ABAP Managed Database Procedures (AMDPs) , that build the bridge between ABAP and SAP HANA, by wrapping SQLScript in ABAP code. You will find all of them in the below overview of our target architecture.
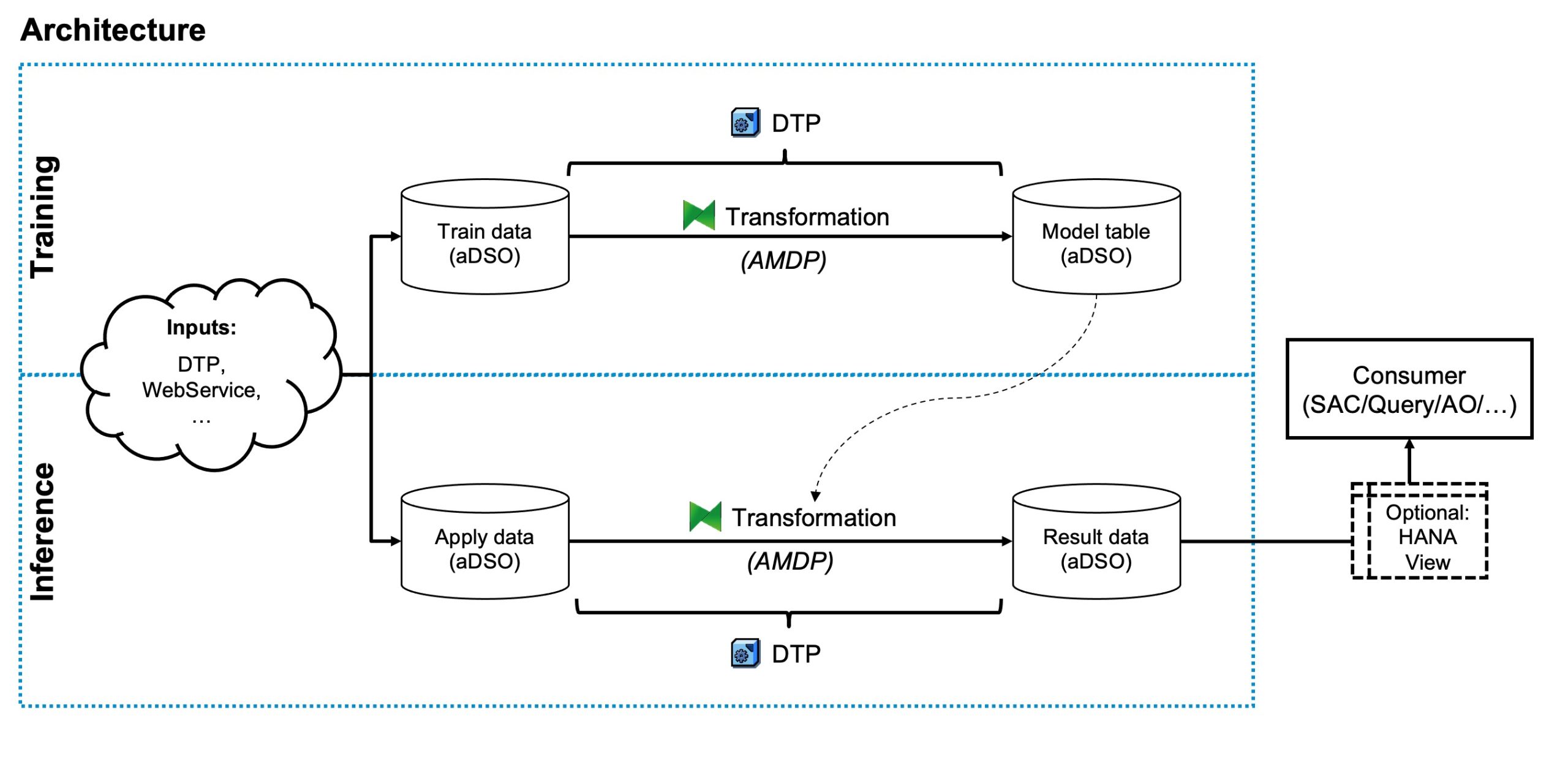 Looking at the picture, you will see that training and inference of the model both look very similar and follow the same scheme:
Looking at the picture, you will see that training and inference of the model both look very similar and follow the same scheme:
- An aDSO storing our input data
- A Transformation that handles either training or inference of the model
- A DTP to trigger the dataload between our source and target-aDSO
- An aDSO that receives the results, either the trained model or the derived predictions
Now, if you have a bit of SAP BW background, this scheme might look odd to you. In typical Data Warehousing scenarios and ETL workloads, a Transformation would only apply minor changes to the data, by performing calculations, string operations, conversions, and the likes. Here, input and output of the Transformation seem to be completely disconnected, but in the end, Machine Learning is in fact just one very complex transformation of data and the good news is: it works great and helps us stay within standard tooling.
With this plan all laid out, we are ready to take a look at the actual system now.
Implementation
For this demo, we will use some made up salary data and predict the corresponding job level, an employee should be associated with, based on some demographic and employment data. The picture below shows an extract of this data.

From here on, we will leverage the tight integration between SAP HANA and SAP BW/4HANA, that allows our Data Scientist to work with native features in SAP HANA as well as Python, while our SAP BW expert keeps maintaining all structures with standard SAP BW tools.
To mimic a standard reporting scenario, the Data Scientist is only given access to a query based on the training data instead of the raw data table. This query automatically translates into an SAP HANA Calculation View that can be accessed using the Python client for SAP HANA Machine Learning. So, experimenting and working with the data from SAP BW feels natural to the Data Scientist. Since our target variable “
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2025 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?