
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPIntegrando o Banco de Dados Snowflake com a Inteligência de Dados SAP: Construindo Operador Personalizado do Snowflake para Carregamento de Dados
- Creado 01/03/2024
- Modificado 01/03/2024
- 29 Vistas
0
Cargando...
Enquanto os dados são um ativo crítico para as empresas modernas, a capacidade da tecnologia de escalar resultou em um grande volume de big data. A gestão e armazenamento de dados evoluíram para se tornar um componente necessário para os processos operacionais modernos.
Snowflake, um data warehouse na nuvem elogiado por sua capacidade de suportar ambientes de infraestrutura multi-cloud, é uma das plataformas de dados mais populares. O Snowflake é um data warehouse que roda em cima da infraestrutura de nuvem da Amazon Web Services ou Microsoft Azure, permitindo que armazenamento e computação escalonem independentemente.
Integrando o Banco de Dados Snowflake com a Inteligência de Dados SAP
Tanto a versão On-Premises quanto a versão Cloud do SAP DI fornecem conectividade com o Banco de Dados Snowflake.
No entanto, até a versão On-Premises 3.2 do SAP DI, não há um operador integrado disponível no modelador DI para suportar a carga de dados no Banco de Dados Snowflake.
Na versão Cloud do SAP DI, há o operador Cloud Table Producer da Geração 2 que suporta a carga de dados no Banco de Dados Snowflake.
Abaixo estão mencionadas algumas limitações do operador Cloud Table Producer:
Para superar esse tipo de desafios/Requisitos, existe a opção disponível na Inteligência de Dados SAP para construir um operador personalizado do Snowflake para carregar dados.
Construindo um Operador Personalizado do Snowflake na Inteligência de Dados SAP.
Para construir o operador personalizado no SAP DI, primeiro devemos cumprir algumas etapas.
1. Construir um arquivo docker no SAP DI para instalar uma biblioteca python do Snowflake.
Ir para a guia Repositório e clicar em criar Arquivo Docker.
Escreva os comandos conforme mostrado na captura de tela, salve e clique em construir.
2. Criar um novo operador personalizado
Ir para a guia Operador e selecionar o operador da Geração 2. Clique no sinal de adição para criar um novo operador. Selecione o Operador Base como Python3 (Geração 2)
3. Ir para a guia de configuração e definir Parâmetros.
Você pode criar parâmetros clicando no botão de edição e definir os detalhes.
4. Selecionar uma imagem de ícone do operador e salvar o operador. Você pode visualizar este operador personalizado visível na guia de operador da Geração 2.
Criar um Gráfico para carregar os Dados das Visualizações CDS do S4H no Banco de Dados Snowflake.
Vamos criar um gráfico para extrair os dados da visualização CDS do S4 Hana e carregá-los na tabela do Snowflake usando o Operador Customizado do Snowflake.
1. Criar um Gráfico Gen2 e Arrastar o Operador "Ler Dados do SAP" no gráfico. Aqui estamos assumindo que para se conectar com a visualização CDS do S4 Hana, criamos um tipo de Conexão RFC ABAP.
Selecione a Conexão, Nome do Objeto e Modo de Transferência na configuração do operador.
2. Arraste o operador Data Transform no gráfico e conecte-o com o Operador Ler Dados do SAP, defina o mapeamento das colunas de saída no operador de transformação.

Snowflake, um data warehouse na nuvem elogiado por sua capacidade de suportar ambientes de infraestrutura multi-cloud, é uma das plataformas de dados mais populares. O Snowflake é um data warehouse que roda em cima da infraestrutura de nuvem da Amazon Web Services ou Microsoft Azure, permitindo que armazenamento e computação escalonem independentemente.
Integrando o Banco de Dados Snowflake com a Inteligência de Dados SAP
Tanto a versão On-Premises quanto a versão Cloud do SAP DI fornecem conectividade com o Banco de Dados Snowflake.
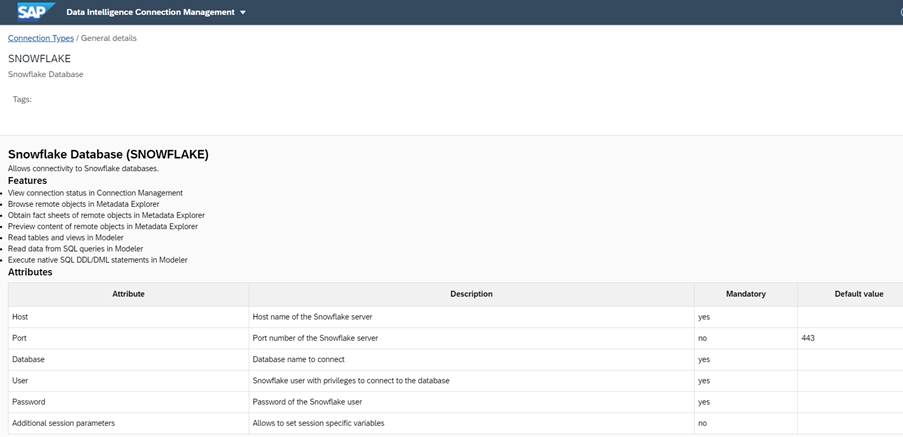
No entanto, até a versão On-Premises 3.2 do SAP DI, não há um operador integrado disponível no modelador DI para suportar a carga de dados no Banco de Dados Snowflake.
Na versão Cloud do SAP DI, há o operador Cloud Table Producer da Geração 2 que suporta a carga de dados no Banco de Dados Snowflake.
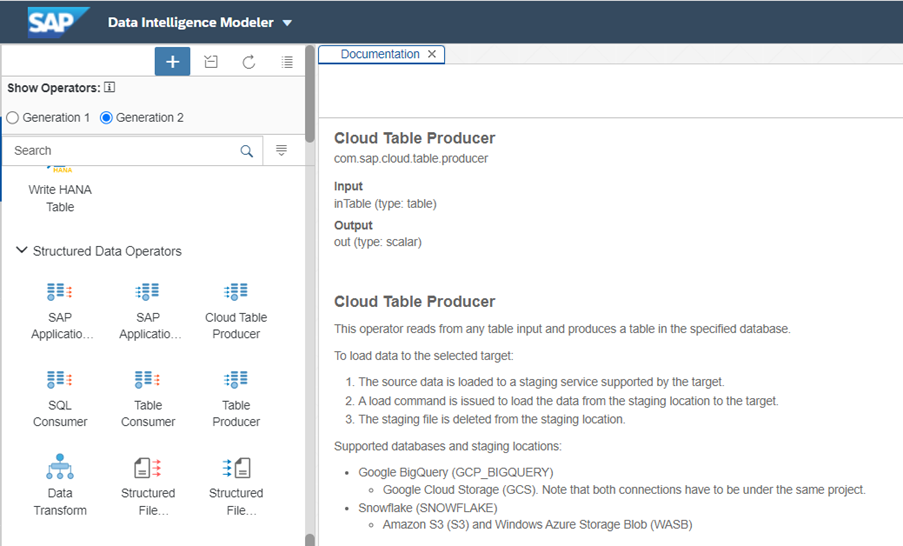
Abaixo estão mencionadas algumas limitações do operador Cloud Table Producer:
- Para carregar os dados no Snowflake, é necessário usar um dos locais de staging (Amazon S3 ou WASB). Não é possível usar este operador se sua infraestrutura atual não incluir nenhum desses armazenamentos em nuvem.
- Não é possível personalizar este operador de acordo com os requisitos, por exemplo, se quisermos realizar UPSERT no Snowflake, este operador não suporta esse modo.
- Este operador é compatível apenas com operadores GEN2, portanto, é necessário projetar os pipelines de acordo.
- Prevenir a perda de registros devido a falhas no gráfico. Suponha que durante o carregamento de dados no Snowflake, o gráfico/pipeline falhe devido a um erro e alguns registros não sejam carregados. Como lidar com os registros falhos?
Para superar esse tipo de desafios/Requisitos, existe a opção disponível na Inteligência de Dados SAP para construir um operador personalizado do Snowflake para carregar dados.
Construindo um Operador Personalizado do Snowflake na Inteligência de Dados SAP.
Para construir o operador personalizado no SAP DI, primeiro devemos cumprir algumas etapas.
1. Construir um arquivo docker no SAP DI para instalar uma biblioteca python do Snowflake.
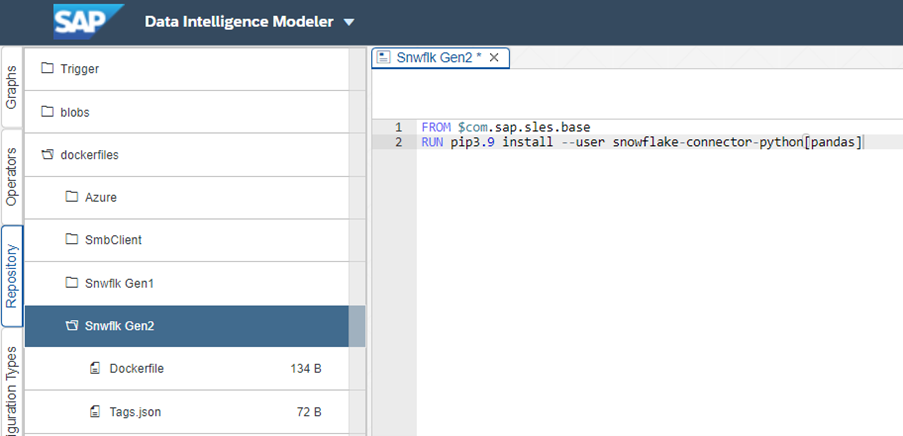
Ir para a guia Repositório e clicar em criar Arquivo Docker.
Escreva os comandos conforme mostrado na captura de tela, salve e clique em construir.
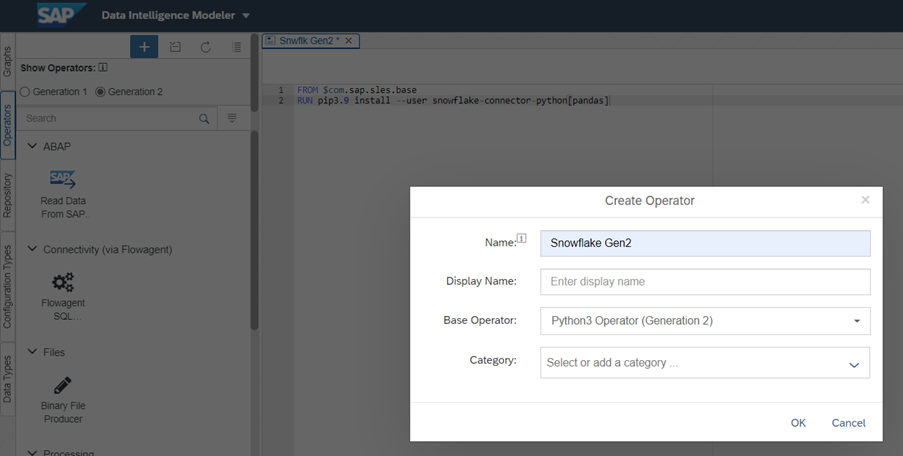
2. Criar um novo operador personalizado
Ir para a guia Operador e selecionar o operador da Geração 2. Clique no sinal de adição para criar um novo operador. Selecione o Operador Base como Python3 (Geração 2)
3. Ir para a guia de configuração e definir Parâmetros.
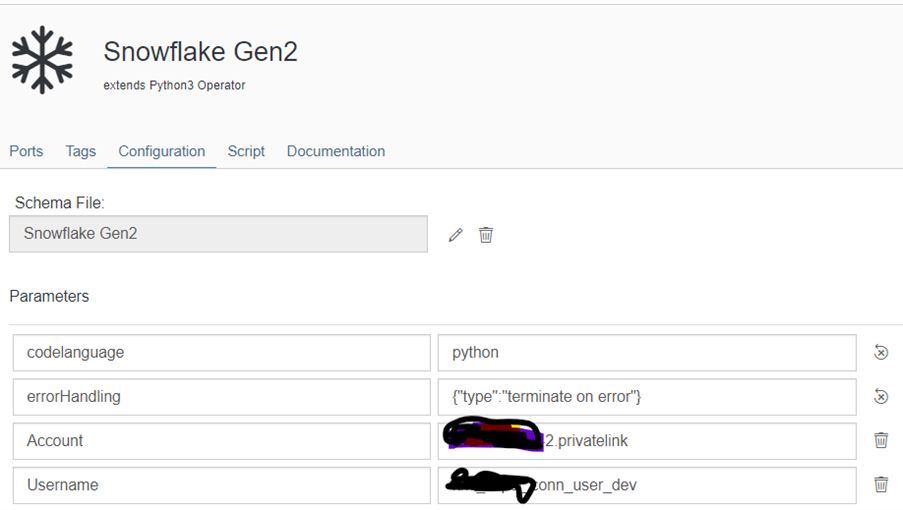
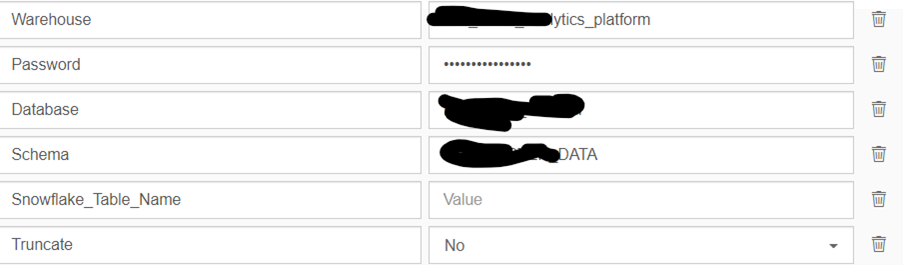
Você pode criar parâmetros clicando no botão de edição e definir os detalhes.
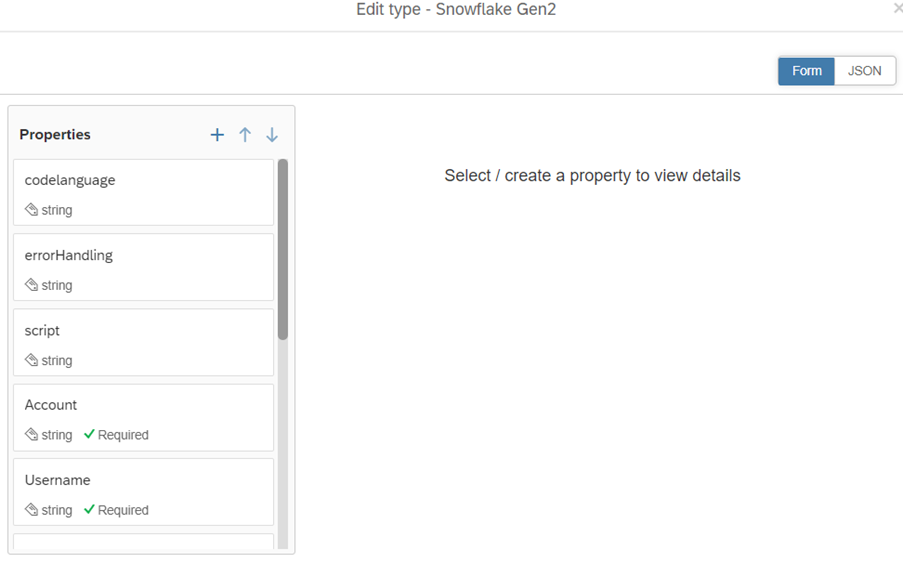
4. Selecionar uma imagem de ícone do operador e salvar o operador. Você pode visualizar este operador personalizado visível na guia de operador da Geração 2.
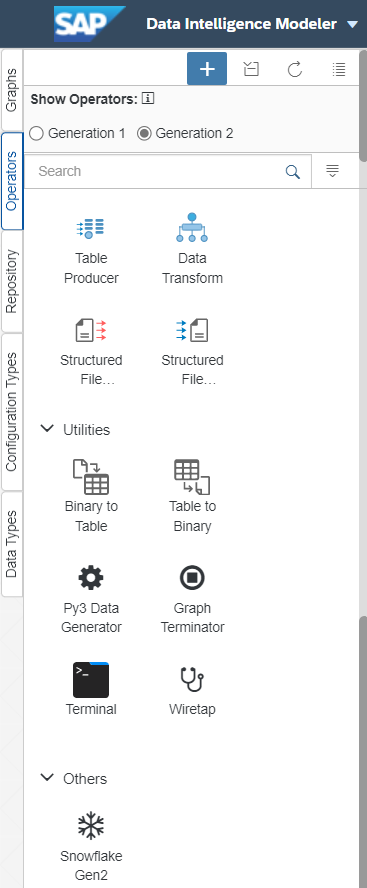
Criar um Gráfico para carregar os Dados das Visualizações CDS do S4H no Banco de Dados Snowflake.
Vamos criar um gráfico para extrair os dados da visualização CDS do S4 Hana e carregá-los na tabela do Snowflake usando o Operador Customizado do Snowflake.
1. Criar um Gráfico Gen2 e Arrastar o Operador "Ler Dados do SAP" no gráfico. Aqui estamos assumindo que para se conectar com a visualização CDS do S4 Hana, criamos um tipo de Conexão RFC ABAP.
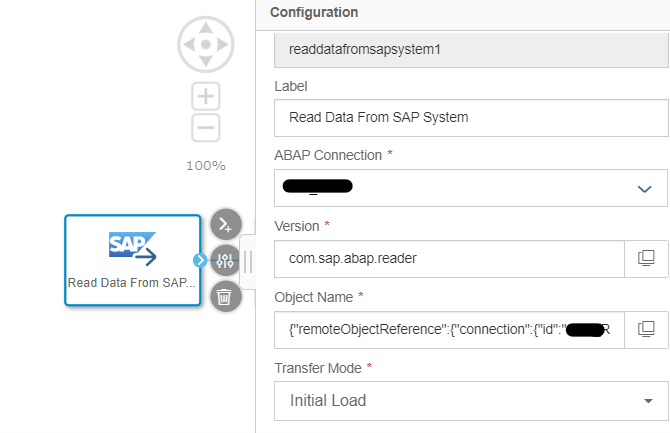
Selecione a Conexão, Nome do Objeto e Modo de Transferência na configuração do operador.
2. Arraste o operador Data Transform no gráfico e conecte-o com o Operador Ler Dados do SAP, defina o mapeamento das colunas de saída no operador de transformação.

Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2025 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?