En la primera parte de este blog doy una introducción a OpenXML en el procesamiento de texto. En la segunda parte proporcionaré código ABAP sobre cómo leer archivos de Word.
Comenzando con Microsoft Word 2007, al crear un nuevo documento en Word y guardarlo, se crea un nuevo archivo con la extensión "*.docx". Este archivo representa archivos xml comprimidos que describen todo el documento de Word. Incluye textos, tablas, tamaños de fuente, colores, comentarios, configuraciones de márgenes, configuraciones de secciones y todo lo que el usuario haya colocado y mantenido manualmente en el documento. Se trata de archivos xml vinculados entre sí en una estructura específica y comprimidos en un archivo.
Para explorar esta estructura, crea tu documento de prueba con algo en él y guárdalo. Cambia la extensión "*.docx" a "*.zip" y descomprime el archivo. Después de descomprimirlo, verás todos los archivos xml en una estructura especificada. Si necesitas verificar y ver estos archivos xml con frecuencia, te recomiendo un método más conveniente. Te sugiero instalar la Herramienta OOXML, que es un complemento para el navegador Chrome. De manera fácil, mediante arrastrar y soltar, puedes ver todo el documento de Word.
Por ejemplo, creé Test.docx con el texto "Hola Mundo". Ten en cuenta que hasta que proporciones alguna entrada en Word, tiene un tamaño de 0. Arrastré el archivo de Word a Chrome usando el complemento mencionado anteriormente para ver la estructura xml del documento de Word. Busqué /word/document.xml para ver la etiqueta de texto que contiene el valor "Hola Mundo".
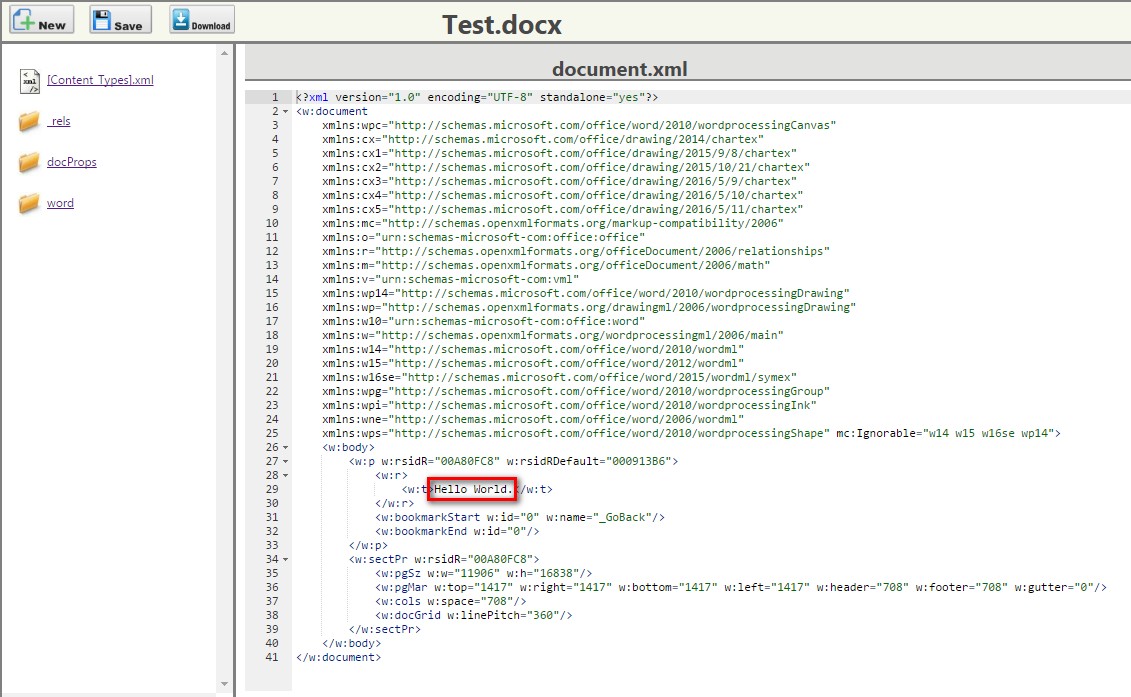
Cada archivo xml describe propiedades para partes del documento o la relación entre las partes. Por ejemplo:
-
Conten_types xml describe el tipo de contenido utilizado en cada parte de todo el documento (paquete)
-
La parte _rels describe la relación entre dos partes
-
La parte de propiedades del documento describe las propiedades generales del documento en el archivo xml de la aplicación y el núcleo (aplicación, autor, versión...)
-
La parte xml personalizada es la parte que puede contener datos específicos del cliente; esto se describirá más en otro blog
-
El contenido del documento se encuentra en el archivo /word/document.xml
-
El xml de la tabla de fuentes contiene información sobre los tipos de fuentes utilizadas
-
El xml de los estilos describe los estilos utilizados
SAP proporciona la clase CL_DOCX_DOCUMENT
que puede ayudarnos a leer y modificar documentos de Word y revisar su estructura. Aquí tienes un código simple que hace el trabajo...
... (código ABAP omitido para reducir la extensión del texto) ...
Los métodos get*part de la clase pueden proporcionar diferentes partes del documento. En este caso, estábamos interesados en la parte principal.
El método get_data( ) te devolverá el archivo xml de la parte y utilizando el método feed_data( ) almacenarás el xml en la parte utilizada del documento. Estos métodos forman parte de cada clase que representa diferentes partes de documentos. Por ejemplo, en nuestro caso es CL_DOCX_MAINDOCUMENTPART. Mira en el depurador
El método get_package_data( ) de la clase CL_DOCX_DOCUMENT guardará todas las partes actuales y las empaquetará en un archivo zip.
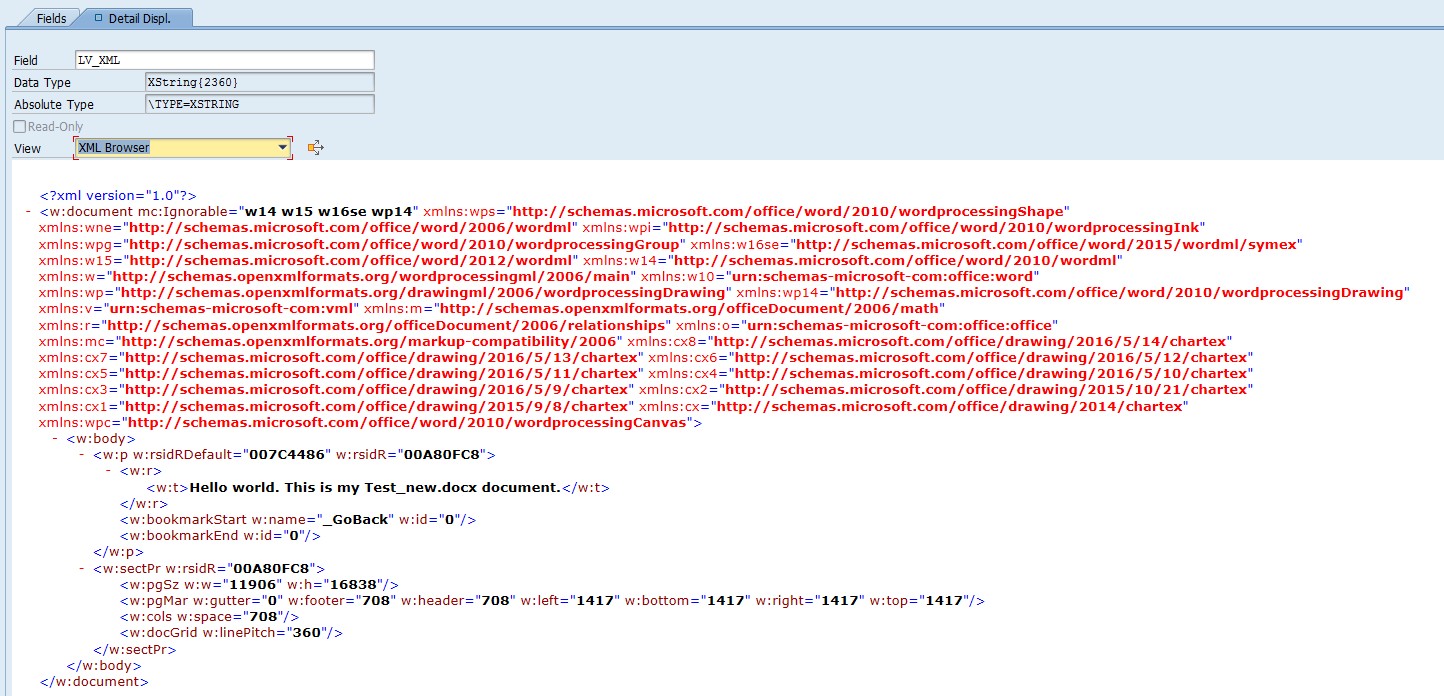
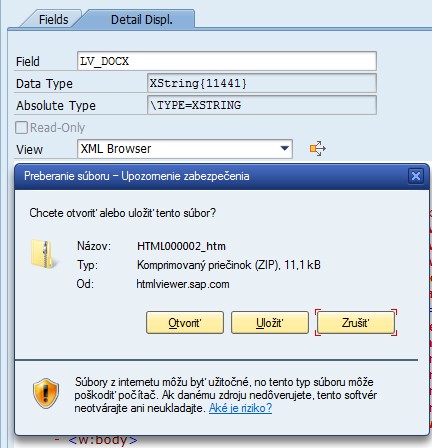
Puedes verificar esto en el depurador al observar las variables lv_xml y lv_docx utilizando la vista del navegador XML. Para la variable lv_xml, verás el archivo xml de la parte principal.
Para lv_docx, se te pedirá un mensaje emergente si deseas guardar el archivo zip, que es el resultado del método get_package_data( ).
En mi
próximo blog
describiré la parte personalizada del documento de Word y cómo puede utilizarla un desarrollador ABAP.


