
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPExperiencias en un Proyecto de Implementación de Replicación HANA a HANA (H2H): Alcance, Arquitectura y Mejores Prácticas
- Creado 01/03/2024
- Modificado 01/03/2024
- 57 Vistas
0
Cargando...
Hi HANA EIM and SDI Community,
In this blog entry I would like to convey some of the experiences we made throughout an SDI HANA to HANA (H2H) implementation project. To gather an understanding of the context, we will start off with the scenario description and solution architecture.
These are the items that will be covered throughout this blog:
- Implementation Scope
- Solution Architecture
- Best Practices
- Challenges
- Reengineering of Replication Tasks
- Monitoring
- Real-time Replication & Source System Archiving
- References
You can expect practical insights into the implementation of a HANA to HANA repliction scenario. Some detailed aspects on e.g. task partitioning, replication task design or monitoring are described. Potentially you can adapt the approaches described in this blog in your own SDI implementation project.
1. Implementation Scope
From an SDI perspective, this brief overview will describe some facts and requirements we had to deal with:
- Replicate data in real-time from 3 different HANA source systems into a (consolidated) target schema using SDI RTs (with the SDI HANAAdapter)
- Replication scope approx. 550 tables per source (times 3 = > 1.600 tables)
- Replicate tables with high record count (6 tables of > 2 billion in production)
- SDI task partitioning for large tables (> 200 mio. records)
- Target table partitioning for large tables (> 200 mio. records)
- SDI infrastructure/configuration – e.g. DP-Agent + Agent groups
- Follow SDI best practice guidelines (naming convention, implementation guidelines, tuning)
- SDI development artifacts maintenance + transport across landscape to PRD
- Dpserver + dpagent monitoring
- Out of scope: Load and replication of IBM DB2 based source systems (compare with architectural diagram)
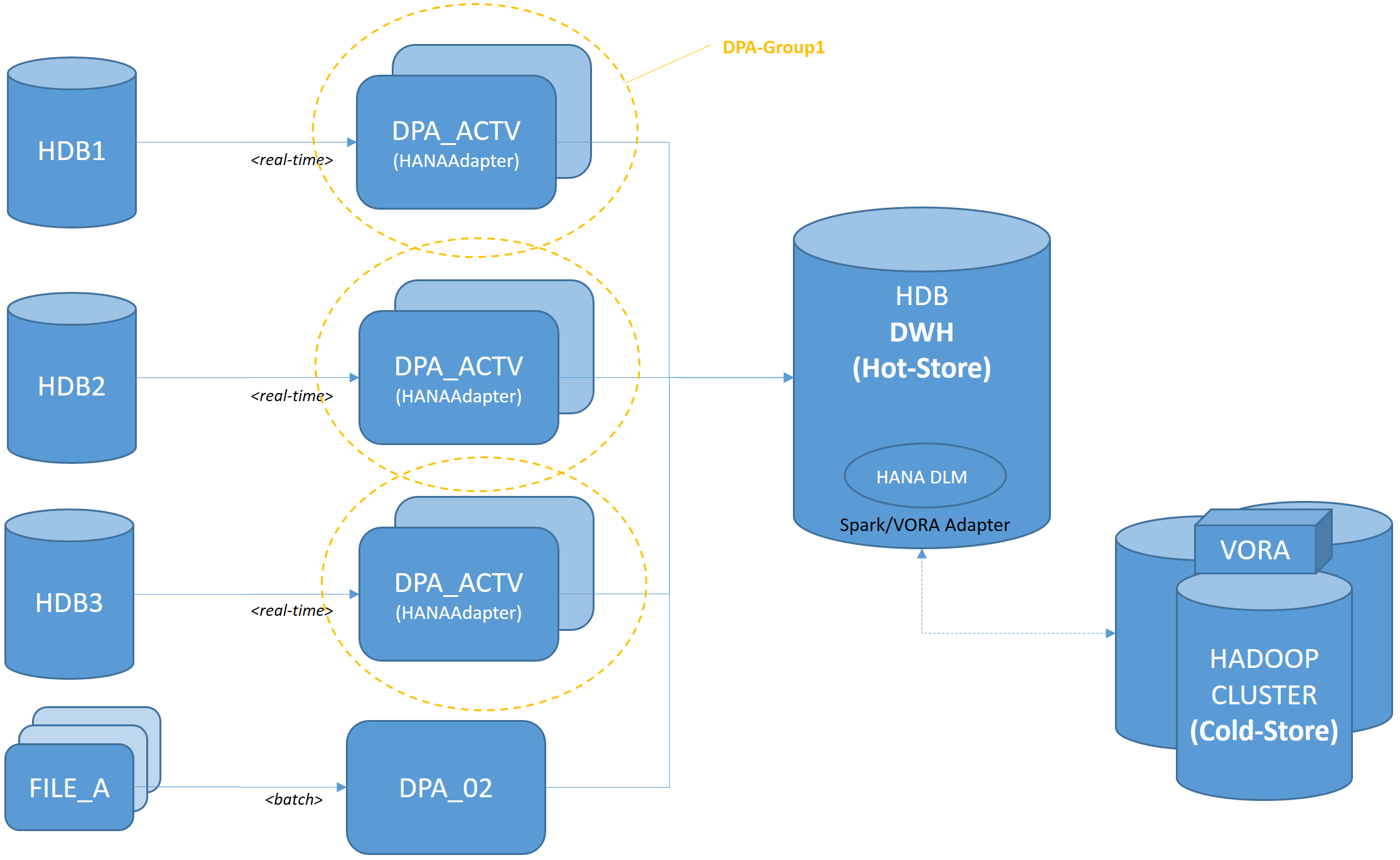
2. Solution Architecture
The end-to-end solution architecture employs several SAP and non-SAP components
-
DP-Agents
- Virtual host on Linux, 64 GB
- 2.1.1
-
HANA 2 SP02
- 4 TB
- HANA EIM SDI (XSC runtime)
- DLM
- HANA Vora 1.4
- Hadoop Cluster with Spark enabled
- Microstrategy
The following illustration shows the architecture in a facilitated way. From an SDI point of view there are multiple real-time + batch input streams: Suite on HANA systems, files, legacy data from IBM DB2 DBs (not shown).
3. SDI Best Practices
Initially, most of the aspects (for users + authorizations) considered in the official SDI Best Practices Guide were implemented(refer to references section for the web link to the bast practices).
SDI users were organized the following way:
- SDI_ADMIN - monitoring privileges, user creation, ***
- SDI_DEV - Web-based development workbench, repository privileges, schema privileges
- SDI_EXEC - execute replication tasks
- SDI_TRANSPORT - transport SDI artifacts
Using this pattern, you can easily follow a segregation of duties approach and avoid unnecessary and unwanted situations in development or deployment. On the contrary, you have to stick with the approach and align your development and administration processes accordingly.
4. SDI Real-time Replication Design – Challenges
The following describes the major challenges we faced:
- Multiple sources into one target
- Replication Task Count
- Duration of Initial Load and Cut-over Time
- Disable the Capture of DDL Changes
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2026 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?