
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPExperiências em um Projeto de Implementação de Replicação HANA para HANA (H2H): Escopo, Arquitetura e Melhores Práticas.
- Creado 01/03/2024
- Modificado 01/03/2024
- 63 Vistas
0
Cargando...
Olá Comunidade HANA EIM e SDI,
Neste post do blog, gostaria de compartilhar algumas das experiências que tivemos durante um projeto de implementação SDI HANA para HANA (H2H). Para entender o contexto, começaremos com a descrição do cenário e a arquitetura da solução.
Estes são os tópicos que serão abordados neste blog:
- Escopo da Implementação
- Arquitetura da Solução
- Melhores Práticas
- Desafios
- Reengenharia de Tarefas de Replicação
- Monitoramento
- Replicação em Tempo Real e Arquivamento do Sistema de Origem
- Referências
Espere obter insights práticos sobre a implementação de um cenário de replicação HANA para HANA. Alguns aspectos detalhados, como particionamento de tarefas, design de tarefas de replicação ou monitoramento, são descritos. Potencialmente, você pode adaptar as abordagens descritas neste blog em seu próprio projeto de implementação SDI.
1. Escopo da Implementação
Do ponto de vista do SDI, esta breve visão geral descreverá alguns fatos e requisitos com os quais tivemos que lidar:
- Replicar dados em tempo real de 3 sistemas de origem HANA diferentes em um esquema de destino (consolidado) usando SDI RTs (com o SDI HANAAdapter)
- Escopo de replicação aproximadamente 550 tabelas por origem (vezes 3 = > 1.600 tabelas)
- Replicar tabelas com alto número de registros (6 tabelas com mais de 2 bilhões em produção)
- Particionamento de tarefas SDI para tabelas grandes (> 200 milhões de registros)
- Particionamento de tabelas de destino para tabelas grandes (> 200 milhões de registros)
- Infraestrutura/configuração do SDI - por exemplo, DP-Agent + grupos de agentes
- Seguir as diretrizes das melhores práticas do SDI (convenção de nomenclatura, diretrizes de implementação, ajustes)
- Manutenção de artefatos de desenvolvimento do SDI + transporte através do ambiente para PRD
- Monitoramento de dpserver + dpagent
- Fora do escopo: Carga e replicação de sistemas de origem baseados em IBM DB2 (comparar com o diagrama arquitetural)
2. Arquitetura da Solução
A arquitetura da solução de ponta a ponta emprega vários componentes SAP e não-SAP
-
DP-Agents
- Host virtual no Linux, 64 GB
- 2.1.1
-
HANA 2 SP02
- 4 TB
- HANA EIM SDI (XSC runtime)
- DLM
- HANA Vora 1.4
- Cluster Hadoop com Spark habilitado
- Microstrategy
A ilustração a seguir mostra a arquitetura de forma facilitada. Do ponto de vista do SDI, existem múltiplos fluxos de entrada em tempo real + em lote: sistemas Suite on HANA, arquivos, dados legados do IBM DB2 DBs (não mostrados).
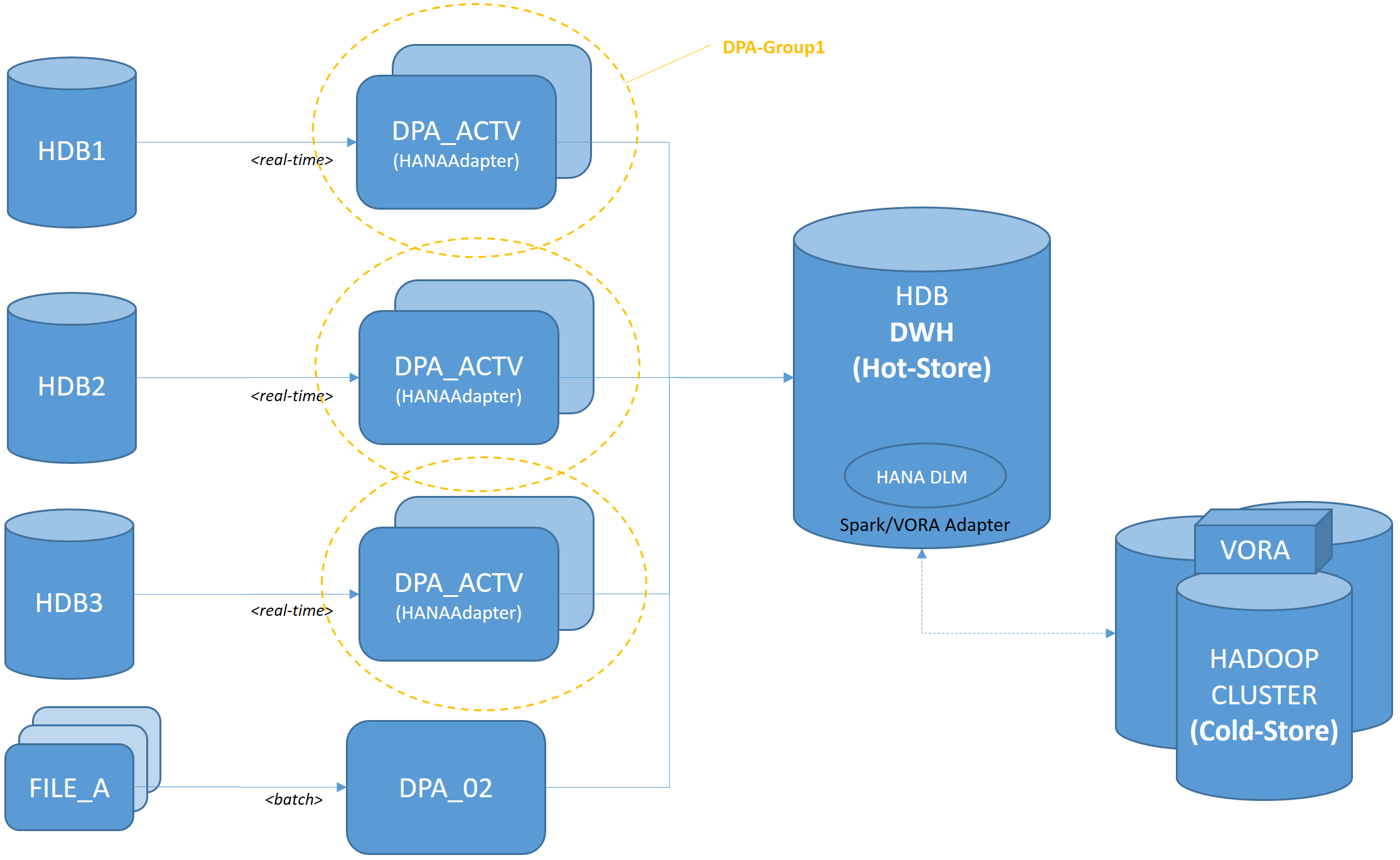
3. Melhores Práticas do SDI
Inicialmente, a maioria dos aspectos (para usuários + autorizações) considerados no Guia Oficial de Melhores Práticas do SDI foram implementados (consulte a seção de referências para o link da web das melhores práticas).
Os usuários do SDI foram organizados da seguinte maneira:
- SDI_ADMIN - privilégios de monitoramento, criação de usuários, ***
- SDI_DEV - bancada de trabalho de desenvolvimento baseada na web, privilégios de repositório, privilégios de esquema
- SDI_EXEC - executar tarefas de replicação
- SDI_TRANSPORT - transportar artefatos do SDI
Usando esse padrão, você pode facilmente seguir uma abordagem de segregação de funções e evitar situações desnecessárias e indesejadas no desenvolvimento ou implantação. Pelo contrário, você deve seguir a abordagem e alinhar seus processos de desenvolvimento e administração de acordo.
4. Design de Replicação em Tempo Real do SDI - Desafios
O seguinte descreve os principais desafios que enfrentamos:
- Múltiplas fontes em um único destino
- Contagem de Tarefas de Replicação
- Duração da Carga Inicial e Tempo de Transição
- Desativar a Captura de Alterações DDL
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2026 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?