Hola.
En comentarios a
otra pregunta
, tanto
Sandra Rossi
como
Matthew Billingham
aconsejaron en contra de esta forma, texto-nnn, mientras que, aparentemente, se debería preferir texto(nnn). Eso captó mi atención y me desconcertó: siempre había asumido que la sintaxis más antigua era texto(nnn) mientras que texto-nnn era más reciente, pero no pude encontrar nada en ABAPDOCU al respecto, de ninguna manera, tal vez porque "texto" es una palabra clave horrible para buscar.
Así que escribí un programa de prueba mínimo en mi entorno de demostración 7.52SP04:
WRITE / 'texto traducible con número al final'(001).
WRITE / 'texto diferente con número al final'(001).
WRITE / TEXTO-002.
WRITE / TEXTO-003.
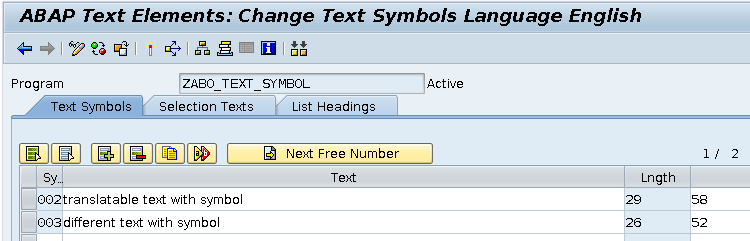
En los símbolos de texto tengo las siguientes definiciones:
Luego revisé la pantalla de traducción:
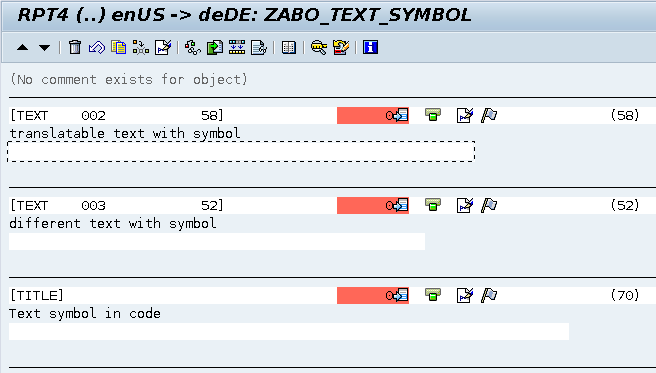
(la única traducción posible es de EN a DE en este sistema)
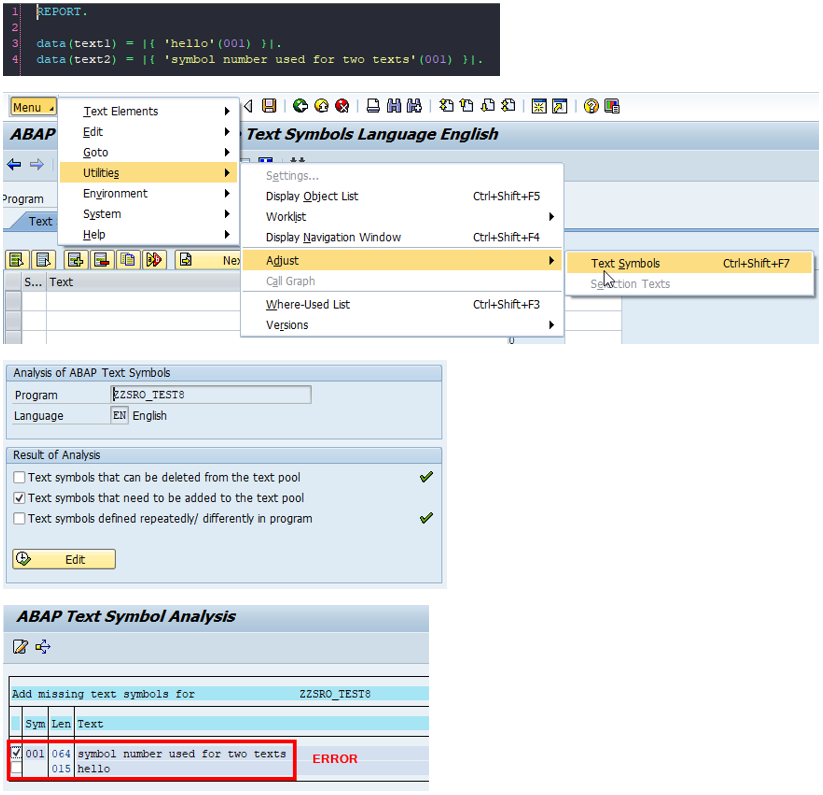
No importa si la línea con la repetición del número está activa o no, en ambos casos la cadena no aparece en la pantalla de traducción. Hasta aquí todo bien: hay que hacer doble clic en el número de texto para crear el símbolo correspondiente, tal como recordaba.
Haz clic en la primera línea y se crea TEXTO-001 con "texto traducible con número al final".
Haz clic en la segunda línea y TEXTO-001 se actualiza con "texto diferente con número al final":

Aquí viene mi pregunta
: ¿cómo se prefiere texto(nnn) como forma cuando puedo escribir un texto diferente con el mismo número y nunca saber cuál es la versión autorizada? Si el código está en un INCLUDE, potencialmente es aún peor.
Desde mi punto de vista, una posible ventaja es que ves el texto en el flujo del programa. No está mal, pero, por otro lado, si tu texto tiene que aparecer varias veces en el código, tienes que escribirlo literalmente cada vez; si quieres cambiarlo, tienes que cambiar todas las ocurrencias en lugar de solo una vez en la definición de los símbolos, de lo contrario te encontrarás con el problema que creé artificialmente arriba.
Aquí está la salida con la versión final del programa: