
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPCómo utilizar un Script básico de Python en SAP Datasphere para actualizar tablas locales
- Creado 01/03/2024
- Modificado 01/03/2024
- 584 Vistas
0
Cargando...
En esta publicación de blog veremos cómo utilizar un Script básico de Python en SAP Datasphere. El objetivo de esta publicación no es enseñarte a codificar en Python experto, pero verás las características elementales de su uso en SAP Datasphere. En lugar de aprender funciones complejas de Python, simplemente verás cómo actualizar o insertar columnas de una tabla local mediante flujos de datos. Para obtener información más detallada y formal, puedes consultar los documentos de SAP.
Supongamos que tenemos una lista de personajes de la película "El Señor de los Anillos (LOTR)". Hemos cargado datos desde un archivo de Excel a una tabla local llamada "TAB_LOTR_001 - Archivo de origen CSV de LOTR" . Por cierto, no voy a mencionar cómo cargar un archivo plano en SAP Datasphere en esta publicación de blog.
Los datos sin procesar de nuestra tabla de entrada son los siguientes:
En esta publicación, me gustaría mostrar la lógica con 2 flujos de datos y 2 tablas de salida. He asumido que ya sabes cómo se crea automáticamente una tabla de salida (tipo: objetivo) en un flujo de datos. Después de crear los siguientes objetos, hemos hecho clic en el botón de Script y agregado el paso de Script de Python entre las tablas de origen y destino:
Tabla de salida: TAB_LOTR_002 - Tabla actualizada de LOTR 1
Flujo de datos: DF_LOTR_001 - Flujo de datos de LOTR 1
Como puedes ver en la imagen anterior, la tabla de destino tiene 6 nuevas columnas que se calcularán en el script pronto.
Puedes agregar nuevas columnas del mismo tipo de datos y longitud que agregaste en la tabla local. Puedes encontrar los pasos a continuación.
Después de que todo esté listo, puedes comenzar a implementar tu código haciendo clic en el botón de lápiz.
Usando las características de Python, puedes actualizar todas las columnas en un solo paso. Aquí puedes ver cómo multiplicar todos los valores en una columna por 2 y escribirlo en una nueva columna.
Primero podemos abrir un for-loop para calcular nuestras nuevas columnas. "len(data)" nos devuelve el número de fila de la tabla y estamos iterando en este rango. La variable "i" es el número de índice es decir, el número de fila comenzando desde cero.
En el primer paso también puedes ver cómo deberíamos haber actualizado una columna actual por "pandas.DataFrame.loc" que actualizará la línea i th y la columna "fila" .
En el segundo paso, el código verifica la columna "birth" y hace un agrupamiento tomando las primeras 2 letras a menos que se mencione como “Antes de la CA” . Por lo tanto, hemos agregado una condición if.
También podemos agrupar la edad de nuestros personajes con un grupo de 0,100,200,1000 y más.
Escenario de caso de uso
Supongamos que tenemos una lista de personajes de la película "El Señor de los Anillos (LOTR)". Hemos cargado datos desde un archivo de Excel a una tabla local llamada "TAB_LOTR_001 - Archivo de origen CSV de LOTR" . Por cierto, no voy a mencionar cómo cargar un archivo plano en SAP Datasphere en esta publicación de blog.
Los datos sin procesar de nuestra tabla de entrada son los siguientes:
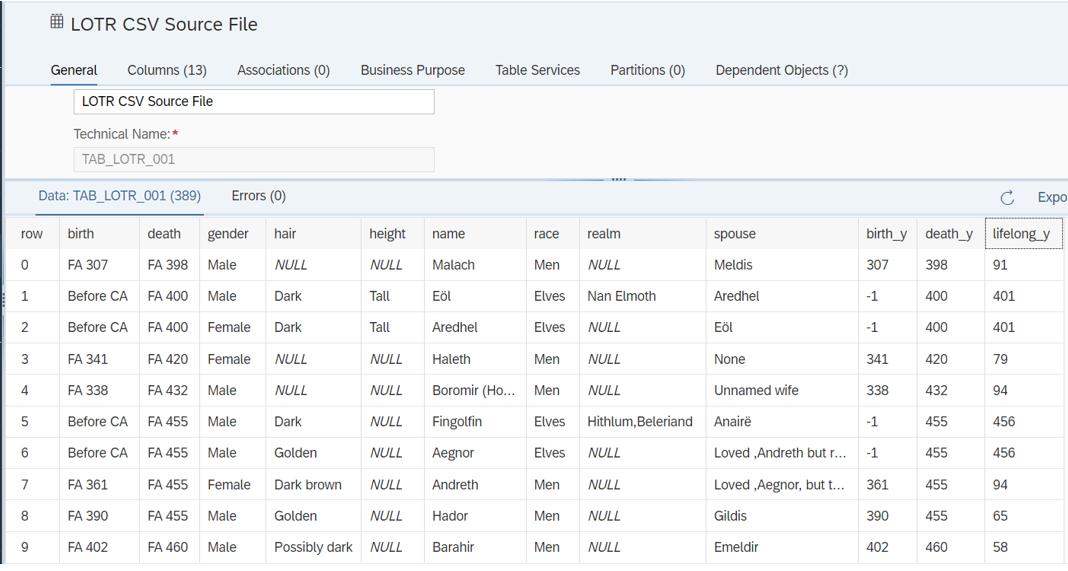
Flujos de datos con Script de Python
En esta publicación, me gustaría mostrar la lógica con 2 flujos de datos y 2 tablas de salida. He asumido que ya sabes cómo se crea automáticamente una tabla de salida (tipo: objetivo) en un flujo de datos. Después de crear los siguientes objetos, hemos hecho clic en el botón de Script y agregado el paso de Script de Python entre las tablas de origen y destino:
Tabla de salida: TAB_LOTR_002 - Tabla actualizada de LOTR 1
Flujo de datos: DF_LOTR_001 - Flujo de datos de LOTR 1
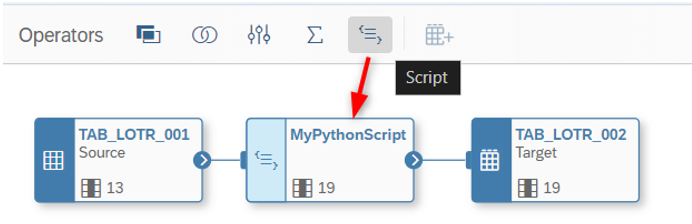
Como puedes ver en la imagen anterior, la tabla de destino tiene 6 nuevas columnas que se calcularán en el script pronto.
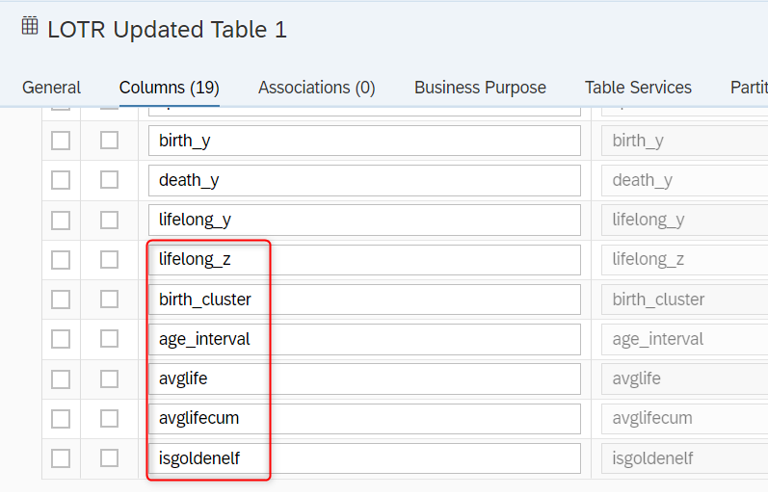
Puedes agregar nuevas columnas del mismo tipo de datos y longitud que agregaste en la tabla local. Puedes encontrar los pasos a continuación.
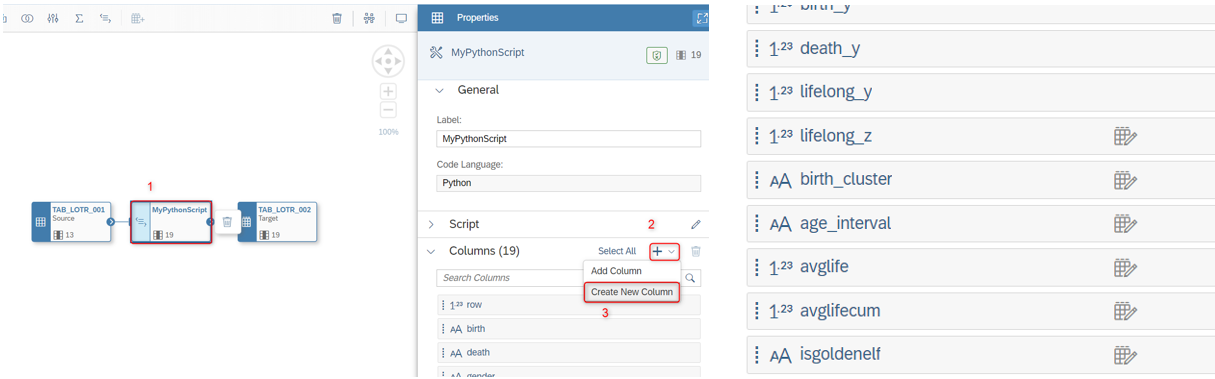
Después de que todo esté listo, puedes comenzar a implementar tu código haciendo clic en el botón de lápiz.
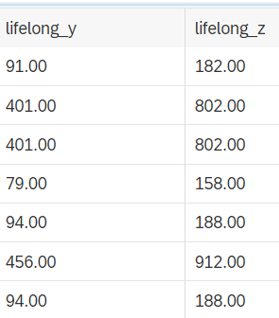
Nueva columna: lifelong_z
Usando las características de Python, puedes actualizar todas las columnas en un solo paso. Aquí puedes ver cómo multiplicar todos los valores en una columna por 2 y escribirlo en una nueva columna.
Nueva columna: birth_cluster
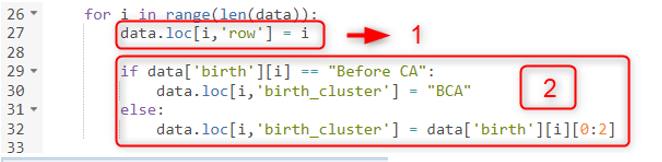
Primero podemos abrir un for-loop para calcular nuestras nuevas columnas. "len(data)" nos devuelve el número de fila de la tabla y estamos iterando en este rango. La variable "i" es el número de índice es decir, el número de fila comenzando desde cero.
En el primer paso también puedes ver cómo deberíamos haber actualizado una columna actual por "pandas.DataFrame.loc" que actualizará la línea i th y la columna "fila" .
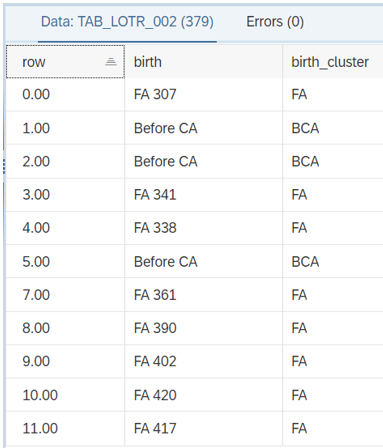
En el segundo paso, el código verifica la columna "birth" y hace un agrupamiento tomando las primeras 2 letras a menos que se mencione como “Antes de la CA” . Por lo tanto, hemos agregado una condición if.
Nueva columna: age_interval
También podemos agrupar la edad de nuestros personajes con un grupo de 0,100,200,1000 y más.
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2026 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?