
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPCómo utilizar datos de un Equipo Scrum para predecir entregas y velocidad
- Creado 01/03/2024
- Modificado 01/03/2024
- 67 Vistas
0
Cargando...
En esta publicación del blog te contaré cómo he recopilado y utilizado los datos de mi equipo Scrum para predecir nuestras entregas y velocidad.
Uno de los conceptos más importantes en las metodologías ágiles es entregar valor y hacerlo constantemente.
Al discutir una nueva funcionalidad para ser entregada a un usuario final, es importante saber cuándo estará lista y disponible para ser utilizada. Por sus principios, ágil se adaptará a medida que avanza, y por lo tanto actualizará con más precisión después de cada iteración la fecha de entrega de cada pequeña pieza de la funcionalidad que estamos apuntando. Si usamos Scrum, la pregunta es: ¿en qué Sprint se hará cada incremento?
Pero, ¿cómo es posible aplicar estimaciones sin caer en un modelo de cascada (planificando con mucha anticipación nuestro proyecto)? Incluso más, ¿es posible lograr precisión en una estimación?
Bueno, permíteme compartir algunas de las prácticas que he estado aplicando en mi Equipo Scrum.
Un poco de antecedentes:
Trabajo como Scrum Master en un Equipo Scrum en S/4 HANA Cloud, tenemos 6 desarrolladores, un Product Owner y un Scrum Master. El equipo es multidisciplinario, es decir, no hay un equipo específico de frontend, backend o incluso de pruebas. Somos un equipo Scrum con solo 3 roles (según la guía de Scrum): Product Owner, Scrum Master y Desarrolladores.
Nos enfrentamos al desafío de crear un nuevo proyecto desde cero, y así surgió la pregunta: ¿cómo sabremos cuándo se puede entregar cada pequeña pieza de incremento?
Para obtener una respuesta a esa pregunta, comencé a recopilar los datos del equipo:
Antes de adentrarnos en el trabajo de datos, me gustaría hablar un poco sobre estimación.
En mi Equipo Scrum usamos la secuencia de Fibonacci para la estimación. ¿Por qué Fibonacci y no horas? Bueno, estamos tratando de estimar el ESFUERZO, y somos conscientes de que no es factible (o posible) tener una precisión perfecta con la estimación en el desarrollo de software.
El desarrollo de software es una actividad tan compleja que me atrevo a decir que es casi imposible saber en la escala de horas cuándo estará lista cada funcionalidad. ¡Por lo tanto, estimamos! Y según la definición, la estimación es: "calcular o juzgar aproximadamente el valor, número, cantidad o extensión de". Así que la secuencia de Fibonacci parece ser una buena opción para determinar tamaños de esfuerzo.
Después de algunos Sprints (justo después de que el equipo se formara, a principios de 2019), recopilé el primer conjunto de datos. No mostraba una consistencia muy buena, como se puede ver en el siguiente gráfico: Puntos de Historia Entregados por Sprint.
Pero, ¿por qué el Equipo Scrum estaba teniendo tantas dificultades para obtener resultados más consistentes?
Después de algunos análisis, surgieron dos razones principales:
El primer tema se resolvió con el tiempo a medida que el equipo construía su química.
Sin embargo, el segundo es un problema común en los Equipos Scrum: ¿están bien descritos y divididos los backlogs?
Para abordar ese problema, el Equipo Scrum adoptó un nuevo enfoque: invertir tiempo del Sprint en Refinamientos de Backlog, lo que significa dedicar un porcentaje de tiempo para esa actividad. Con eso, los desarrolladores se acercaron más a las definiciones
Uno de los conceptos más importantes en las metodologías ágiles es entregar valor y hacerlo constantemente.
Al discutir una nueva funcionalidad para ser entregada a un usuario final, es importante saber cuándo estará lista y disponible para ser utilizada. Por sus principios, ágil se adaptará a medida que avanza, y por lo tanto actualizará con más precisión después de cada iteración la fecha de entrega de cada pequeña pieza de la funcionalidad que estamos apuntando. Si usamos Scrum, la pregunta es: ¿en qué Sprint se hará cada incremento?
Pero, ¿cómo es posible aplicar estimaciones sin caer en un modelo de cascada (planificando con mucha anticipación nuestro proyecto)? Incluso más, ¿es posible lograr precisión en una estimación?
Bueno, permíteme compartir algunas de las prácticas que he estado aplicando en mi Equipo Scrum.
Un poco de antecedentes:
Trabajo como Scrum Master en un Equipo Scrum en S/4 HANA Cloud, tenemos 6 desarrolladores, un Product Owner y un Scrum Master. El equipo es multidisciplinario, es decir, no hay un equipo específico de frontend, backend o incluso de pruebas. Somos un equipo Scrum con solo 3 roles (según la guía de Scrum): Product Owner, Scrum Master y Desarrolladores.
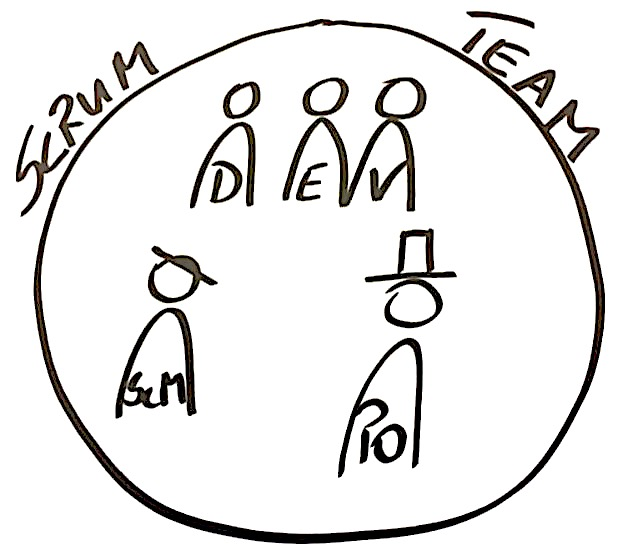
Nos enfrentamos al desafío de crear un nuevo proyecto desde cero, y así surgió la pregunta: ¿cómo sabremos cuándo se puede entregar cada pequeña pieza de incremento?
Para obtener una respuesta a esa pregunta, comencé a recopilar los datos del equipo:
- Duración del Sprint
- Disponibilidad del equipo
- Estimación
- Entregado
Antes de adentrarnos en el trabajo de datos, me gustaría hablar un poco sobre estimación.
En mi Equipo Scrum usamos la secuencia de Fibonacci para la estimación. ¿Por qué Fibonacci y no horas? Bueno, estamos tratando de estimar el ESFUERZO, y somos conscientes de que no es factible (o posible) tener una precisión perfecta con la estimación en el desarrollo de software.
El desarrollo de software es una actividad tan compleja que me atrevo a decir que es casi imposible saber en la escala de horas cuándo estará lista cada funcionalidad. ¡Por lo tanto, estimamos! Y según la definición, la estimación es: "calcular o juzgar aproximadamente el valor, número, cantidad o extensión de". Así que la secuencia de Fibonacci parece ser una buena opción para determinar tamaños de esfuerzo.

Después de algunos Sprints (justo después de que el equipo se formara, a principios de 2019), recopilé el primer conjunto de datos. No mostraba una consistencia muy buena, como se puede ver en el siguiente gráfico: Puntos de Historia Entregados por Sprint.
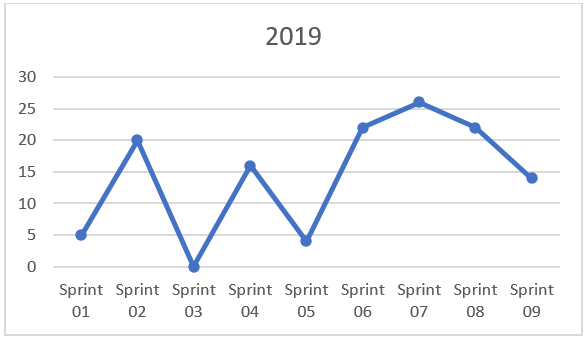
Entregas de 2019 por Sprint
Pero, ¿por qué el Equipo Scrum estaba teniendo tantas dificultades para obtener resultados más consistentes?
Después de algunos análisis, surgieron dos razones principales:
- El equipo era nuevo y, por lo tanto, aún estaba buscando la mejor manera de trabajar juntos.
- Los backlogs no estaban siendo suficientemente refinados.
El primer tema se resolvió con el tiempo a medida que el equipo construía su química.
Sin embargo, el segundo es un problema común en los Equipos Scrum: ¿están bien descritos y divididos los backlogs?
Para abordar ese problema, el Equipo Scrum adoptó un nuevo enfoque: invertir tiempo del Sprint en Refinamientos de Backlog, lo que significa dedicar un porcentaje de tiempo para esa actividad. Con eso, los desarrolladores se acercaron más a las definiciones
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2026 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?