
Aprende en Comunidad
Avalados por :


Como usar um Script básico de Python no SAP Datasphere para atualizar tabelas locais
- Creado 01/03/2024
- Modificado 01/03/2024
- 9 Vistas
0
Cargando...
Neste post do blog, veremos como usar um Script básico de Python no SAP Datasphere. O objetivo deste post não é ensinar a codificar em Python como um especialista, mas sim mostrar as características básicas de seu uso no SAP Datasphere. Em vez de aprender funções complexas do Python, você verá como atualizar ou inserir colunas em uma tabela local por meio de fluxos de dados. Para obter informações mais detalhadas e formais, consulte os documentos da SAP.
Suponha que temos uma lista de personagens do filme "O Senhor dos Anéis (LOTR)". Carregamos dados de um arquivo do Excel para uma tabela local chamada "TAB_LOTR_001 - Arquivo de origem CSV do LOTR" . Por sinal, não vou mencionar como carregar um arquivo plano no SAP Datasphere neste post do blog.
Os dados brutos de nossa tabela de entrada são os seguintes:
Neste post, gostaria de mostrar a lógica com 2 fluxos de dados e 2 tabelas de saída. Pressuponho que você já saiba como criar automaticamente uma tabela de saída (tipo: alvo) em um fluxo de dados. Após criar os seguintes objetos, clicamos no botão de Script e adicionamos a etapa de Script de Python entre as tabelas de origem e destino:
Tabela de saída: TAB_LOTR_002 - Tabela atualizada do LOTR 1
Fluxo de dados: DF_LOTR_001 - Fluxo de dados do LOTR 1
Como você pode ver na imagem acima, a tabela de destino tem 6 novas colunas que serão calculadas no script em breve.
Você pode adicionar novas colunas do mesmo tipo de dados e comprimento que adicionou na tabela local. Você pode encontrar os passos abaixo.
Depois de tudo pronto, você pode começar a implementar seu código clicando no botão de lápis.
Usando as características do Python, você pode atualizar todas as colunas em um único passo. Aqui você pode ver como multiplicar todos os valores em uma coluna por 2 e escrevê-los em uma nova coluna.
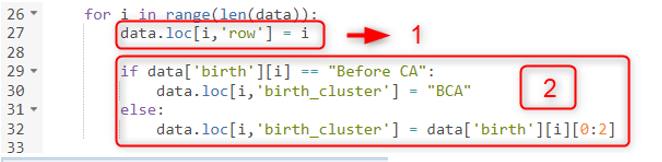
Primeiro, podemos abrir um for-loop para calcular nossas novas colunas. "len(data)" nos dá o número de linhas da tabela e estamos iterando neste intervalo. A variável "i" é o índice, ou seja, o número da linha começando do zero.
No primeiro passo, você também pode ver como deveríamos ter atualizado uma coluna existente usando "pandas.DataFrame.loc" que atualizará a linha i th e a coluna "coluna" .
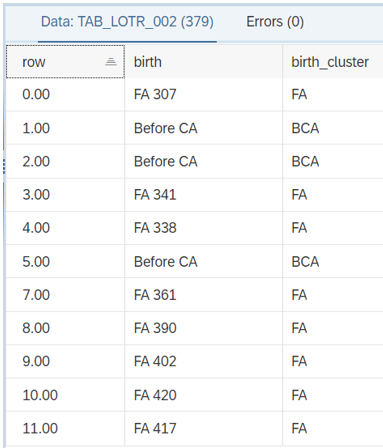
No segundo passo, o código verifica a coluna "birth" e faz um agrupamento pegando as duas primeiras letras, a menos que seja mencionado como Antes da CA . Portanto, adicionamos uma condição if.
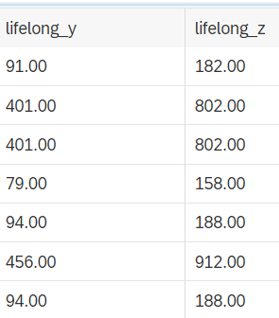
Também podemos agrupar a idade de nossos personagens com um intervalo de 0,100,200,1000 e mais.
Cenário de caso de uso
Suponha que temos uma lista de personagens do filme "O Senhor dos Anéis (LOTR)". Carregamos dados de um arquivo do Excel para uma tabela local chamada "TAB_LOTR_001 - Arquivo de origem CSV do LOTR" . Por sinal, não vou mencionar como carregar um arquivo plano no SAP Datasphere neste post do blog.
Os dados brutos de nossa tabela de entrada são os seguintes:
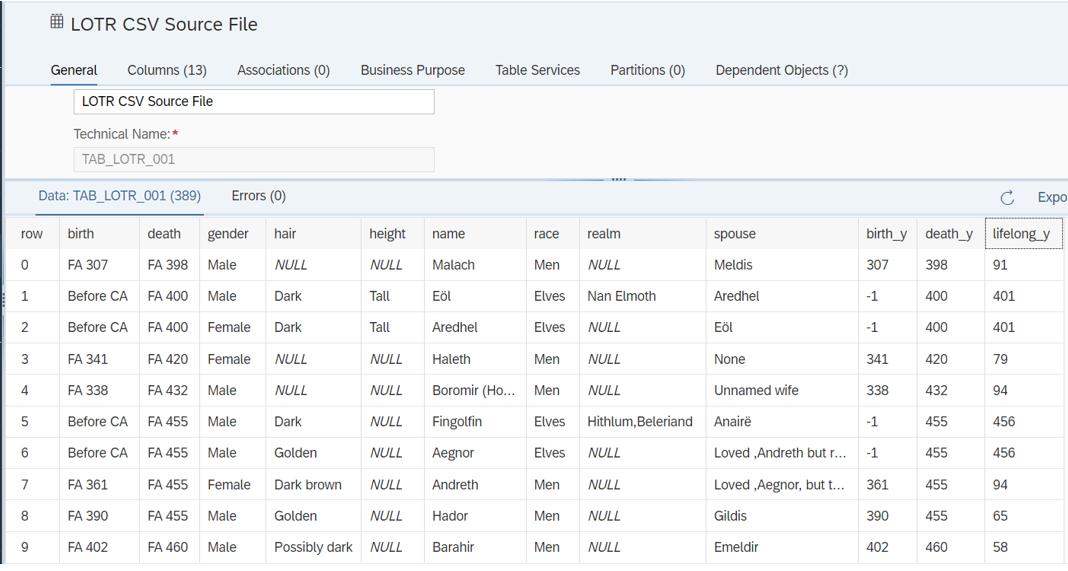
Fluxos de dados com Script de Python
Neste post, gostaria de mostrar a lógica com 2 fluxos de dados e 2 tabelas de saída. Pressuponho que você já saiba como criar automaticamente uma tabela de saída (tipo: alvo) em um fluxo de dados. Após criar os seguintes objetos, clicamos no botão de Script e adicionamos a etapa de Script de Python entre as tabelas de origem e destino:
Tabela de saída: TAB_LOTR_002 - Tabela atualizada do LOTR 1
Fluxo de dados: DF_LOTR_001 - Fluxo de dados do LOTR 1
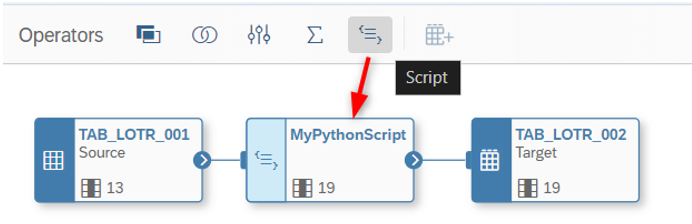
Como você pode ver na imagem acima, a tabela de destino tem 6 novas colunas que serão calculadas no script em breve.
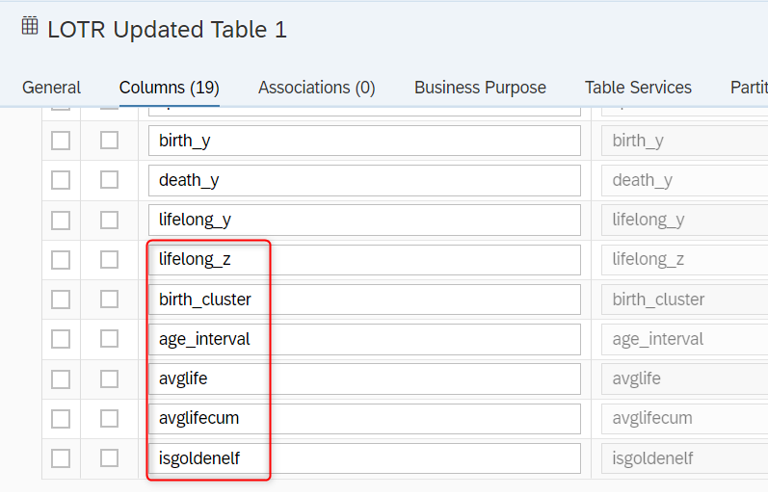
Você pode adicionar novas colunas do mesmo tipo de dados e comprimento que adicionou na tabela local. Você pode encontrar os passos abaixo.
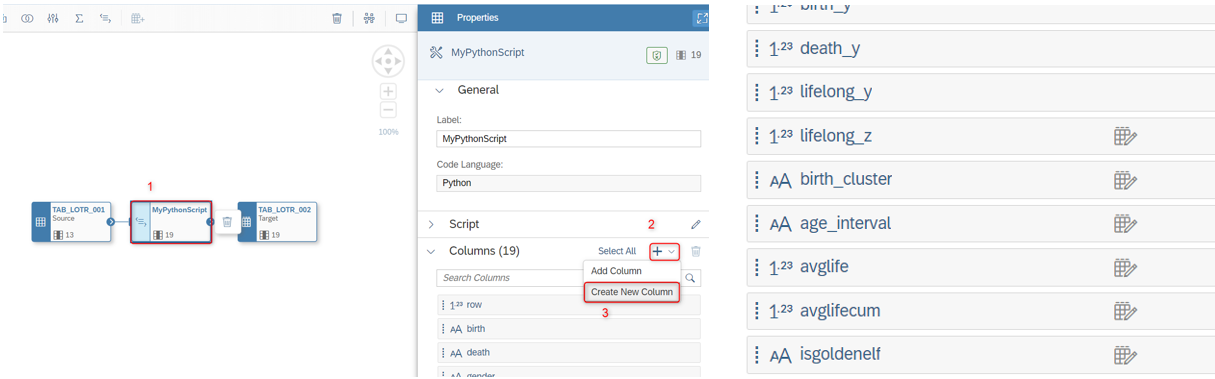
Depois de tudo pronto, você pode começar a implementar seu código clicando no botão de lápis.
Nova coluna: lifelong_z
Usando as características do Python, você pode atualizar todas as colunas em um único passo. Aqui você pode ver como multiplicar todos os valores em uma coluna por 2 e escrevê-los em uma nova coluna.
Nova coluna: birth_cluster
Primeiro, podemos abrir um for-loop para calcular nossas novas colunas. "len(data)" nos dá o número de linhas da tabela e estamos iterando neste intervalo. A variável "i" é o índice, ou seja, o número da linha começando do zero.
No primeiro passo, você também pode ver como deveríamos ter atualizado uma coluna existente usando "pandas.DataFrame.loc" que atualizará a linha i th e a coluna "coluna" .
No segundo passo, o código verifica a coluna "birth" e faz um agrupamento pegando as duas primeiras letras, a menos que seja mencionado como Antes da CA . Portanto, adicionamos uma condição if.
Nova coluna: age_interval
Também podemos agrupar a idade de nossos personagens com um intervalo de 0,100,200,1000 e mais.
Pedro Pascal
Se unió el 07/03/2018
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
contacto@primeinstitute.com
(+51) 1641 9379
(+57) 1489 6964
© 2025 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute