
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPComo usar dados de uma equipe Scrum para prever entregas e velocidade
- Creado 01/03/2024
- Modificado 01/03/2024
- 60 Vistas
0
Cargando...
Nesta postagem do blog, vou contar como compilei e utilizei os dados da minha equipe Scrum para prever nossas entregas e velocidade.
Um dos conceitos mais importantes nas metodologias ágeis é entregar valor e fazê-lo constantemente.
Ao discutir uma nova funcionalidade a ser entregue a um usuário final, é importante saber quando estará pronta e disponível para uso. Por seus princípios, o ágil se adaptará à medida que avança, e portanto atualizará com mais precisão após cada iteração a data de entrega de cada pequena parte da funcionalidade que estamos visando. Se usarmos o Scrum, a pergunta é: em que Sprint será feito cada incremento?
Mas, como é possível fazer estimativas sem cair em um modelo cascata (planejando com muita antecedência nosso projeto)? Ainda mais, é possível alcançar precisão em uma estimativa?
Bem, deixe-me compartilhar algumas das práticas que tenho aplicado em minha Equipe Scrum.
Um pouco de antecedentes:
Trabalho como Scrum Master em uma Equipe Scrum no S/4 HANA Cloud, temos 6 desenvolvedores, um Product Owner e um Scrum Master. A equipe é multidisciplinar, ou seja, não há uma equipe específica de frontend, backend ou mesmo de testes. Somos uma equipe Scrum com apenas 3 papéis (segundo o guia do Scrum): Product Owner, Scrum Master e Desenvolvedores.
Enfrentamos o desafio de criar um novo projeto do zero, e assim surgiu a pergunta: como saberemos quando cada pequena parte do incremento pode ser entregue?
Para obter uma resposta a essa pergunta, comecei a compilar os dados da equipe:
Antes de mergulhar no trabalho de dados, gostaria de falar um pouco sobre estimativa.
Em minha Equipe Scrum, usamos a sequência de Fibonacci para a estimativa. Por que Fibonacci e não horas? Bem, estamos tentando estimar o ESFORÇO, e somos conscientes de que não é factível (ou possível) ter uma precisão perfeita na estimativa no desenvolvimento de software. O desenvolvimento de software é uma atividade tão complexa que me atrevo a dizer que é quase impossível saber em escala de horas quando cada funcionalidade estará pronta. Portanto, estimamos! E de acordo com a definição, a estimativa é: "calcular ou julgar aproximadamente o valor, número, quantidade ou extensão de". Então, a sequência de Fibonacci parece ser uma boa opção para determinar tamanhos de esforço.
Depois de alguns Sprints (logo após a formação da equipe, no início de 2019), compilei o primeiro conjunto de dados. Não mostrava uma consistência muito boa, como pode ser visto no gráfico a seguir: Pontos de História Entregues por Sprint.
Mas, por que a Equipe Scrum estava tendo tantas dificuldades para obter resultados mais consistentes?
Depois de algumas análises, surgiram duas razões principais:
O primeiro problema foi resolvido com o tempo à medida que a equipe construía sua química.
No entanto, o segundo é um problema comum nas Equipes Scrum: os backlogs estão bem descritos e divididos?
Para abordar esse problema, a Equipe Scrum adotou uma nova abordagem: investir tempo do Sprint em Refinamentos de Backlog, o que significa dedicar uma porcentagem de tempo para essa atividade. Com isso, os desenvolvedores se aproximaram mais das definições
Um dos conceitos mais importantes nas metodologias ágeis é entregar valor e fazê-lo constantemente.
Ao discutir uma nova funcionalidade a ser entregue a um usuário final, é importante saber quando estará pronta e disponível para uso. Por seus princípios, o ágil se adaptará à medida que avança, e portanto atualizará com mais precisão após cada iteração a data de entrega de cada pequena parte da funcionalidade que estamos visando. Se usarmos o Scrum, a pergunta é: em que Sprint será feito cada incremento?
Mas, como é possível fazer estimativas sem cair em um modelo cascata (planejando com muita antecedência nosso projeto)? Ainda mais, é possível alcançar precisão em uma estimativa?
Bem, deixe-me compartilhar algumas das práticas que tenho aplicado em minha Equipe Scrum.
Um pouco de antecedentes:
Trabalho como Scrum Master em uma Equipe Scrum no S/4 HANA Cloud, temos 6 desenvolvedores, um Product Owner e um Scrum Master. A equipe é multidisciplinar, ou seja, não há uma equipe específica de frontend, backend ou mesmo de testes. Somos uma equipe Scrum com apenas 3 papéis (segundo o guia do Scrum): Product Owner, Scrum Master e Desenvolvedores.
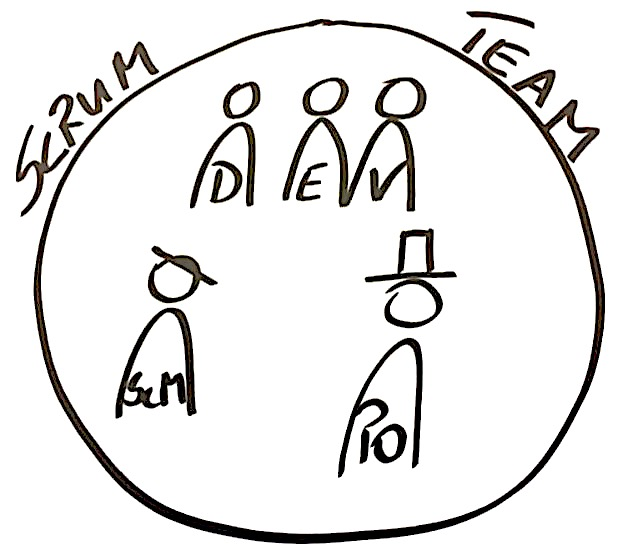
Enfrentamos o desafio de criar um novo projeto do zero, e assim surgiu a pergunta: como saberemos quando cada pequena parte do incremento pode ser entregue?
Para obter uma resposta a essa pergunta, comecei a compilar os dados da equipe:
- Duração do Sprint
- Disponibilidade da equipe
- Estimativa
- Entregue
Antes de mergulhar no trabalho de dados, gostaria de falar um pouco sobre estimativa.
Em minha Equipe Scrum, usamos a sequência de Fibonacci para a estimativa. Por que Fibonacci e não horas? Bem, estamos tentando estimar o ESFORÇO, e somos conscientes de que não é factível (ou possível) ter uma precisão perfeita na estimativa no desenvolvimento de software. O desenvolvimento de software é uma atividade tão complexa que me atrevo a dizer que é quase impossível saber em escala de horas quando cada funcionalidade estará pronta. Portanto, estimamos! E de acordo com a definição, a estimativa é: "calcular ou julgar aproximadamente o valor, número, quantidade ou extensão de". Então, a sequência de Fibonacci parece ser uma boa opção para determinar tamanhos de esforço.

Depois de alguns Sprints (logo após a formação da equipe, no início de 2019), compilei o primeiro conjunto de dados. Não mostrava uma consistência muito boa, como pode ser visto no gráfico a seguir: Pontos de História Entregues por Sprint.
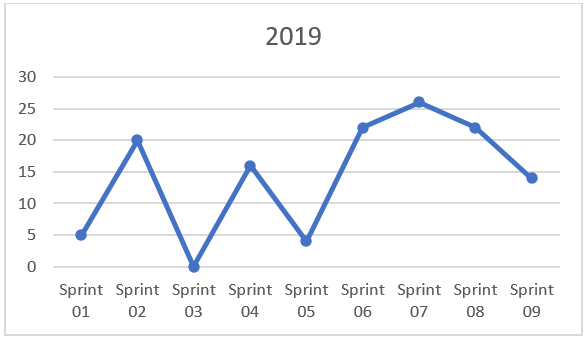
Entregas de 2019 por Sprint
Mas, por que a Equipe Scrum estava tendo tantas dificuldades para obter resultados mais consistentes?
Depois de algumas análises, surgiram duas razões principais:
- A equipe era nova e, portanto, ainda estava buscando a melhor maneira de trabalhar juntos.
- Os backlogs não estavam sendo suficientemente refinados.
O primeiro problema foi resolvido com o tempo à medida que a equipe construía sua química.
No entanto, o segundo é um problema comum nas Equipes Scrum: os backlogs estão bem descritos e divididos?
Para abordar esse problema, a Equipe Scrum adotou uma nova abordagem: investir tempo do Sprint em Refinamentos de Backlog, o que significa dedicar uma porcentagem de tempo para essa atividade. Com isso, os desenvolvedores se aproximaram mais das definições
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2026 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?