


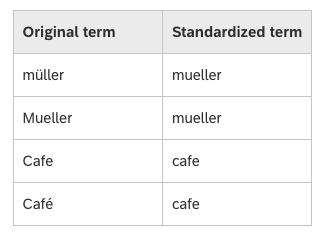
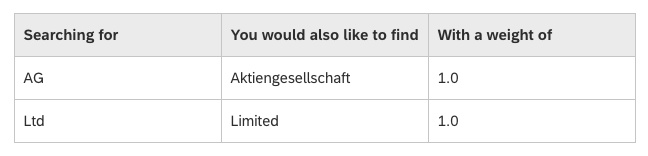
 Detalhes sobre como a Pesquisa SAP HANA padroniza letras podem ser encontrados aqui:
Detalhes sobre como a Pesquisa SAP HANA padroniza letras podem ser encontrados aqui:


0
Cargando...
Olá Trond,
você descreve em seu blog https://blogs.sap.com/2023/03/07/how-does-sap-hana-search-work-in-sap-global-trade-services-sanction...
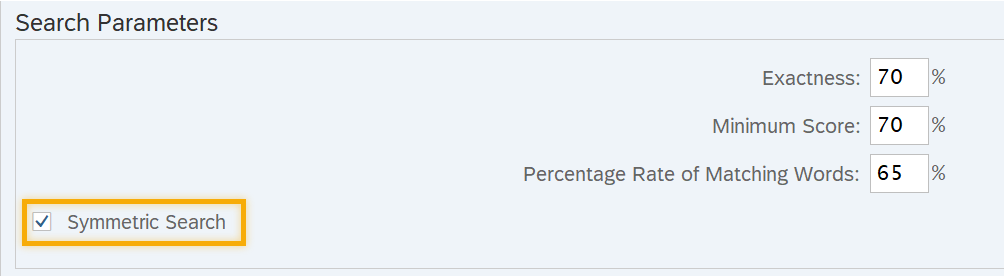
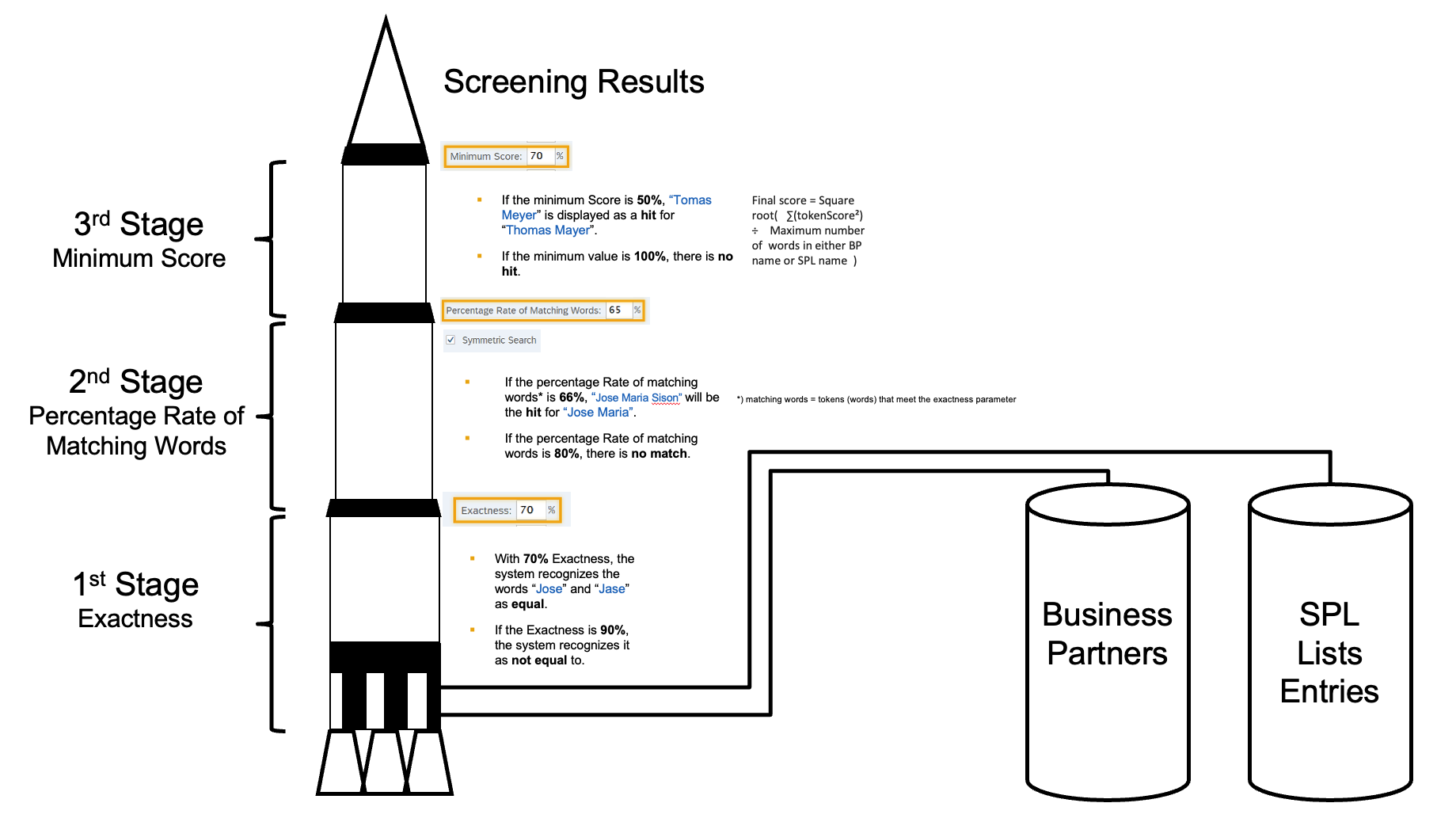
dentro da seção "Comprimento mínimo" ... No entanto, uma vez que a geração de termos de pesquisa não é mais necessária com o SAP HANA Search, esses parâmetros não estão mais em vigor quando o SAP HANA Search é utilizado ...
que a geração de termos de pesquisa não é mais necessária.
A documentação da SAP "Guia de Administração | PÚBLICO 2023-03-21 SAP Global Trade Services, edição para SAP HANA" inclui os seguintes capítulos "6.2.2.5 Gerenciar Termos de Comparação para Listas de Partes Sancionadas", 6.2.2.6 Termos de Comparação para Dados Mestres da SPL e "6.2.2.7 Geração de Termos de Comparação para Dados Mestres de BP" que podem não ser mais necessários. Você pode confirmar isso e acionar uma alteração nos documentos da SAP?
O capítulo "6.2.2.8 Redefinir o Buffer de Aplicação" é, do meu ponto de vista, apenas necessário quando ocorrem alterações no customizing. Minha compreensão está correta?
Obrigado pelo seu feedback antecipadamente.
você descreve em seu blog https://blogs.sap.com/2023/03/07/how-does-sap-hana-search-work-in-sap-global-trade-services-sanction...
dentro da seção "Comprimento mínimo" ... No entanto, uma vez que a geração de termos de pesquisa não é mais necessária com o SAP HANA Search, esses parâmetros não estão mais em vigor quando o SAP HANA Search é utilizado ...
que a geração de termos de pesquisa não é mais necessária.
A documentação da SAP "Guia de Administração | PÚBLICO 2023-03-21 SAP Global Trade Services, edição para SAP HANA" inclui os seguintes capítulos "6.2.2.5 Gerenciar Termos de Comparação para Listas de Partes Sancionadas", 6.2.2.6 Termos de Comparação para Dados Mestres da SPL e "6.2.2.7 Geração de Termos de Comparação para Dados Mestres de BP" que podem não ser mais necessários. Você pode confirmar isso e acionar uma alteração nos documentos da SAP?
O capítulo "6.2.2.8 Redefinir o Buffer de Aplicação" é, do meu ponto de vista, apenas necessário quando ocorrem alterações no customizing. Minha compreensão está correta?
Obrigado pelo seu feedback antecipadamente.
Respondido el 15/04/2024
LUCIANO RIOJA GHIOTTO
Se unió el 13/07/2019