
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPCómo manejar archivos de texto enormes en CPI de SAP: Guía completa
- Creado 01/03/2024
- Modificado 01/03/2024
- 288 Vistas
0
Cargando...
Introducción:
Manejar archivos de texto enormes (que son csv o de longitud fija) es un desafío en CPI (Integración de la Plataforma en la Nube de SAP).
Mayormente, antes de convertirlos a xml requerido para el mapeo, los leemos a través de scripts de groovy y también manipulamos los datos. A menudo esto se hace convirtiéndolos a formato de cadena, lo cual consume mucha memoria.
En esta publicación del blog, mostraré formas alternativas de manejarlos, no solo cómo leer archivos grandes, sino también cómo manipularlos.
Espero que disfrutes la lectura.
Sección Principal:
En CPI (Integración de la Plataforma en la Nube de SAP) a veces nos encontramos con escenarios donde necesitamos procesar un archivo de texto de entrada csv u otro delimitado por caracteres.
A menudo estos archivos son enormes en comparación con cuando recibimos datos en formato xml o json.
Esta fecha que puede ser delimitada por ",", tabulación o "|" o de longitud fija, crea complejidad adicional ya que primero deben ser leídos, ordenados, convertidos a xml (para mapear a alguna estructura de destino) antes de que puedan ser finalmente procesados. Además, a veces tenemos que hacer varias verificaciones en el número de campos para validar si una línea en el archivo vale la pena procesar o no, de antemano, para detener el flujo de datos innecesarios.
Como: Archivo -> input.csv
A,12234,NO,C,20190711,……
A,26579,NO,D,20190701,…….
……………………………………………..
……………………………………………..
Digamos que tenemos que procesar todas las líneas del archivo anterior donde el cuarto campo tiene la bandera establecida en 'D', o indicador de débito.
Entonces, en el ejemplo anterior después de leer el archivo, solo deberíamos mantener las líneas que tengan 'D' como cuarto campo y por lo tanto la línea 1 anterior no debería procesarse más.
Aquí abajo veremos cómo manejar archivos de texto, csv. Especialmente, archivos enormes y cómo procesar cada línea de ellos sin convertir a String lo cual consume más memoria.
*. Leyendo archivos grandes:
Normalmente comenzamos nuestros scripts convirtiendo la carga de entrada en un Objeto de Cadena.
String contenido = message.getBody(String) // esta línea se usa principalmente en scripts.
Pero en caso de archivos grandes, la línea anterior convierte todos los datos a String y los almacena en memoria, lo cual no es para nada una buena práctica. Además, cualquier cambio nuevo en ellos al crear o reemplazar con nuevos Objetos de Cadena ocupa más espacio. Esto también tiene la probabilidad de tener un - Error de Memoria Insuficiente.
La mejor manera es manejarlos como flujo. Hay dos clases que pueden manejar datos de flujo.
a. java.io.Reader -> maneja datos como flujo de caracteres o texto
b. java.io.InputStream -> maneja datos como flujo crudo o binario.
Dependiendo del nivel de control que necesites sobre los datos, o requisito comercial puedes usar uno de ellos. Mayormente la clase Reader es más fácil de usar ya que obtenemos datos como texto/caracter (UTF-16) en lugar de datos binarios crudos (UTF-8).
Leyendo Datos en script groovy de CPI a través de java.io.Reader :
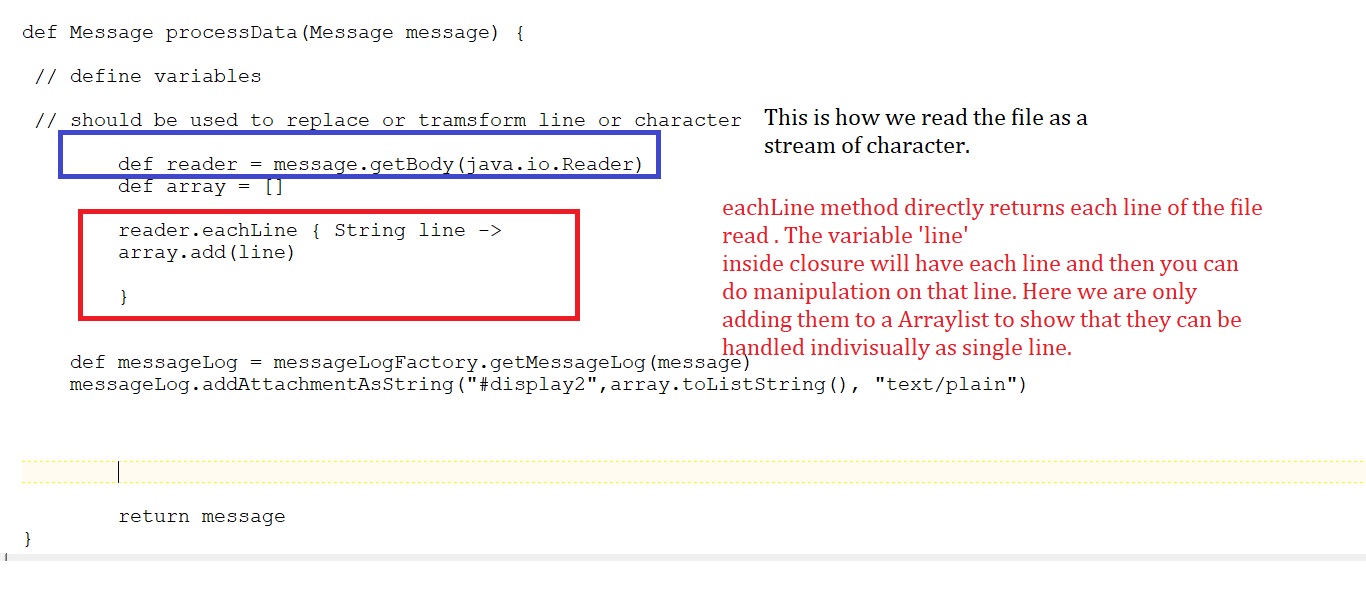
Leyendo Datos en cada campo o nivel de palabra, para cada línea :

*. No es una buena forma de hacer reemplazos en datos en CPI Groovy :
La forma de hacerlo con String -

El mejor enfoque de hacer un reemplazo mientras se lee como Flujo :

*. Leyendo carga como un objeto java.io.InputStream, flujo de objeto:


Manejar archivos de texto enormes (que son csv o de longitud fija) es un desafío en CPI (Integración de la Plataforma en la Nube de SAP).
Mayormente, antes de convertirlos a xml requerido para el mapeo, los leemos a través de scripts de groovy y también manipulamos los datos. A menudo esto se hace convirtiéndolos a formato de cadena, lo cual consume mucha memoria.
En esta publicación del blog, mostraré formas alternativas de manejarlos, no solo cómo leer archivos grandes, sino también cómo manipularlos.
Espero que disfrutes la lectura.
Sección Principal:
En CPI (Integración de la Plataforma en la Nube de SAP) a veces nos encontramos con escenarios donde necesitamos procesar un archivo de texto de entrada csv u otro delimitado por caracteres.
A menudo estos archivos son enormes en comparación con cuando recibimos datos en formato xml o json.
Esta fecha que puede ser delimitada por ",", tabulación o "|" o de longitud fija, crea complejidad adicional ya que primero deben ser leídos, ordenados, convertidos a xml (para mapear a alguna estructura de destino) antes de que puedan ser finalmente procesados. Además, a veces tenemos que hacer varias verificaciones en el número de campos para validar si una línea en el archivo vale la pena procesar o no, de antemano, para detener el flujo de datos innecesarios.
Como: Archivo -> input.csv
A,12234,NO,C,20190711,……
A,26579,NO,D,20190701,…….
……………………………………………..
……………………………………………..
Digamos que tenemos que procesar todas las líneas del archivo anterior donde el cuarto campo tiene la bandera establecida en 'D', o indicador de débito.
Entonces, en el ejemplo anterior después de leer el archivo, solo deberíamos mantener las líneas que tengan 'D' como cuarto campo y por lo tanto la línea 1 anterior no debería procesarse más.
Aquí abajo veremos cómo manejar archivos de texto, csv. Especialmente, archivos enormes y cómo procesar cada línea de ellos sin convertir a String lo cual consume más memoria.
*. Leyendo archivos grandes:
Normalmente comenzamos nuestros scripts convirtiendo la carga de entrada en un Objeto de Cadena.
String contenido = message.getBody(String) // esta línea se usa principalmente en scripts.
Pero en caso de archivos grandes, la línea anterior convierte todos los datos a String y los almacena en memoria, lo cual no es para nada una buena práctica. Además, cualquier cambio nuevo en ellos al crear o reemplazar con nuevos Objetos de Cadena ocupa más espacio. Esto también tiene la probabilidad de tener un - Error de Memoria Insuficiente.
La mejor manera es manejarlos como flujo. Hay dos clases que pueden manejar datos de flujo.
a. java.io.Reader -> maneja datos como flujo de caracteres o texto
b. java.io.InputStream -> maneja datos como flujo crudo o binario.
Dependiendo del nivel de control que necesites sobre los datos, o requisito comercial puedes usar uno de ellos. Mayormente la clase Reader es más fácil de usar ya que obtenemos datos como texto/caracter (UTF-16) en lugar de datos binarios crudos (UTF-8).
Leyendo Datos en script groovy de CPI a través de java.io.Reader :
Leyendo Datos en cada campo o nivel de palabra, para cada línea :
*. No es una buena forma de hacer reemplazos en datos en CPI Groovy :
La forma de hacerlo con String -
El mejor enfoque de hacer un reemplazo mientras se lee como Flujo :
*. Leyendo carga como un objeto java.io.InputStream, flujo de objeto:
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2026 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?