
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPComo lidar com arquivos de texto enormes no CPI da SAP: Guia completo
- Creado 01/03/2024
- Modificado 01/03/2024
- 20 Vistas
0
Cargando...
Introdução:
Manipular arquivos de texto enormes (que são csv ou de comprimento fixo) é um desafio no CPI (Integração da Plataforma na Nuvem da SAP).
Geralmente, antes de convertê-los em xml necessário para o mapeamento, os lemos através de scripts groovy e também manipulamos os dados. Frequentemente isso é feito convertendo-os para o formato de string, o que consome muita memória.
Neste post do blog, mostrarei formas alternativas de lidar com eles, não apenas como ler arquivos grandes, mas também como manipulá-los.
Espero que goste da leitura.
Seção Principal:
No CPI (Integração da Plataforma na Nuvem da SAP) às vezes nos deparamos com cenários onde precisamos processar um arquivo de texto de entrada csv ou outro delimitado por caracteres.
Muitas vezes esses arquivos são enormes em comparação com quando recebemos dados em formato xml ou json.
Essa data que pode ser delimitada por ",", tabulação ou "|" ou de comprimento fixo, cria complexidade adicional, pois primeiro devem ser lidos, ordenados, convertidos em xml (para mapear para alguma estrutura de destino) antes que possam ser finalmente processados. Além disso, às vezes temos que fazer várias verificações no número de campos para validar se uma linha no arquivo vale a pena processar ou não, antecipadamente, para interromper o fluxo de dados desnecessários.
Como: Arquivo -> input.csv
A,12234,NO,C,20190711,
A,26579,NO,D,20190701, .
..
..
Digamos que temos que processar todas as linhas do arquivo anterior onde o quarto campo tem a bandeira definida como 'D', ou indicador de débito.
Então, no exemplo anterior após ler o arquivo, só devemos manter as linhas que têm 'D' como quarto campo e, portanto, a linha 1 anterior não deve ser processada mais.
Abaixo veremos como lidar com arquivos de texto, csv. Especialmente, arquivos enormes e como processar cada linha deles sem converter em String o que consome mais memória.
*. Lendo arquivos grandes:
Normalmente começamos nossos scripts convertendo a carga de entrada em um Objeto de String.
String conteúdo = message.getBody(String) // esta linha é usada principalmente em scripts.
Mas no caso de arquivos grandes, a linha anterior converte todos os dados em String e os armazena na memória, o que não é de forma alguma uma boa prática. Além disso, qualquer nova alteração neles ao criar ou substituir por novos Objetos de String ocupa mais espaço. Isso também tem a probabilidade de ter um - Erro de Memória Insuficiente.
A melhor maneira é lidar com eles como fluxo. Existem duas classes que podem lidar com dados de fluxo.
a. java.io.Reader -> lida com dados como fluxo de caracteres ou texto
b. java.io.InputStream -> lida com dados como fluxo bruto ou binário.
Dependendo do nível de controle que você precisa sobre os dados, ou requisito comercial, você pode usar um deles. Geralmente a classe Reader é mais fácil de usar, pois obtemos dados como texto/caractere (UTF-16) em vez de dados binários brutos (UTF-8).
Lendo Dados em script groovy do CPI através de java.io.Reader :
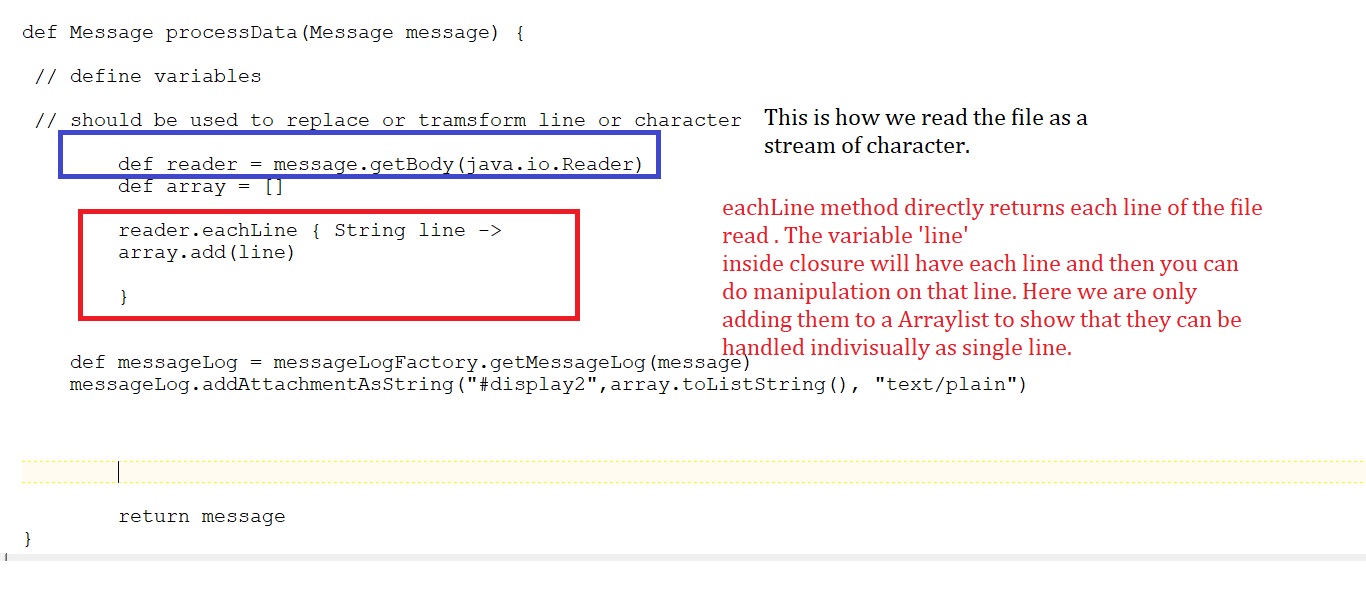
Lendo Dados em cada campo ou nível de palavra, para cada linha :

*. Não é uma boa forma de fazer substituições em dados no CPI Groovy :
A forma de fazer com String -

A melhor abordagem para fazer uma substituição enquanto se lê como Fluxo :

*. Lendo carga como um objeto java.io.InputStream, fluxo de objeto:


Manipular arquivos de texto enormes (que são csv ou de comprimento fixo) é um desafio no CPI (Integração da Plataforma na Nuvem da SAP).
Geralmente, antes de convertê-los em xml necessário para o mapeamento, os lemos através de scripts groovy e também manipulamos os dados. Frequentemente isso é feito convertendo-os para o formato de string, o que consome muita memória.
Neste post do blog, mostrarei formas alternativas de lidar com eles, não apenas como ler arquivos grandes, mas também como manipulá-los.
Espero que goste da leitura.
Seção Principal:
No CPI (Integração da Plataforma na Nuvem da SAP) às vezes nos deparamos com cenários onde precisamos processar um arquivo de texto de entrada csv ou outro delimitado por caracteres.
Muitas vezes esses arquivos são enormes em comparação com quando recebemos dados em formato xml ou json.
Essa data que pode ser delimitada por ",", tabulação ou "|" ou de comprimento fixo, cria complexidade adicional, pois primeiro devem ser lidos, ordenados, convertidos em xml (para mapear para alguma estrutura de destino) antes que possam ser finalmente processados. Além disso, às vezes temos que fazer várias verificações no número de campos para validar se uma linha no arquivo vale a pena processar ou não, antecipadamente, para interromper o fluxo de dados desnecessários.
Como: Arquivo -> input.csv
A,12234,NO,C,20190711,
A,26579,NO,D,20190701, .
..
..
Digamos que temos que processar todas as linhas do arquivo anterior onde o quarto campo tem a bandeira definida como 'D', ou indicador de débito.
Então, no exemplo anterior após ler o arquivo, só devemos manter as linhas que têm 'D' como quarto campo e, portanto, a linha 1 anterior não deve ser processada mais.
Abaixo veremos como lidar com arquivos de texto, csv. Especialmente, arquivos enormes e como processar cada linha deles sem converter em String o que consome mais memória.
*. Lendo arquivos grandes:
Normalmente começamos nossos scripts convertendo a carga de entrada em um Objeto de String.
String conteúdo = message.getBody(String) // esta linha é usada principalmente em scripts.
Mas no caso de arquivos grandes, a linha anterior converte todos os dados em String e os armazena na memória, o que não é de forma alguma uma boa prática. Além disso, qualquer nova alteração neles ao criar ou substituir por novos Objetos de String ocupa mais espaço. Isso também tem a probabilidade de ter um - Erro de Memória Insuficiente.
A melhor maneira é lidar com eles como fluxo. Existem duas classes que podem lidar com dados de fluxo.
a. java.io.Reader -> lida com dados como fluxo de caracteres ou texto
b. java.io.InputStream -> lida com dados como fluxo bruto ou binário.
Dependendo do nível de controle que você precisa sobre os dados, ou requisito comercial, você pode usar um deles. Geralmente a classe Reader é mais fácil de usar, pois obtemos dados como texto/caractere (UTF-16) em vez de dados binários brutos (UTF-8).
Lendo Dados em script groovy do CPI através de java.io.Reader :
Lendo Dados em cada campo ou nível de palavra, para cada linha :
*. Não é uma boa forma de fazer substituições em dados no CPI Groovy :
A forma de fazer com String -
A melhor abordagem para fazer uma substituição enquanto se lê como Fluxo :
*. Lendo carga como um objeto java.io.InputStream, fluxo de objeto:
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2025 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?