Hi Experts,
Tenho um caso de uso em que estou chamando um endpoint da CPI, passando a URL de uma imagem jpeg hospedada (como esta:
http://braiden.net/images/img.jpg
) e então faço uma solicitação GET para essa URL usando uma solicitação-resposta para obter os dados da imagem bruta no corpo da mensagem.
Construí com sucesso essa parte. Agora que tenho esses dados de imagem bruta no corpo da mensagem, gostaria de fazer uma solicitação-resposta ao serviço de Reconhecimento Óptico de Caracteres da SAP (
documentado aqui
).
Esta API requer que a solicitação seja formatada da seguinte maneira:
Content-Type: multipart/form-data; boundary=CPI
APIKey: [alguma-chave-api-válida]
Content-Length: [comprimento-do-conteúdo]
-
Deve conter um corpo de formulário múltiplo, com um único campo chamado "files" que contenha os dados da imagem
Devido aos requisitos da solicitação para esta API, adicionei um modificador de conteúdo para remover todos os cabeçalhos desnecessários (que podem ter sido trazidos da primeira solicitação) e adicionar os cabeçalhos necessários. (Parece que o cabeçalho "Content-Length" é adicionado automaticamente pela CPI, e qualquer tentativa de alterar/remover este cabeçalho não funciona).
Dentro deste modificador de conteúdo, também adicionei o seguinte no corpo como uma expressão:
--CPI
Content-Disposition: form-data; name="files"; filename="img.jpg"
Content-Type: image/jpeg
${body}
--CPI--
Isso envolve os dados da imagem bruta com as informações de limite necessárias para o tipo de conteúdo multipart/form-data. (Este método de envolver dados brutos foi retirado de
esta postagem no blog
.)
Aqui está uma imagem do meu fluxo de integração:

Clique aqui
para baixar este fluxo de integração como um arquivo zip.
Uma coisa que notei é que ao enviar a solicitação do Postman versus fazer a solicitação da CPI é que o valor do cabeçalho Content-Length é drasticamente diferente, e como mencionei, parece não haver maneira de definir manualmente este cabeçalho para um valor diferente.
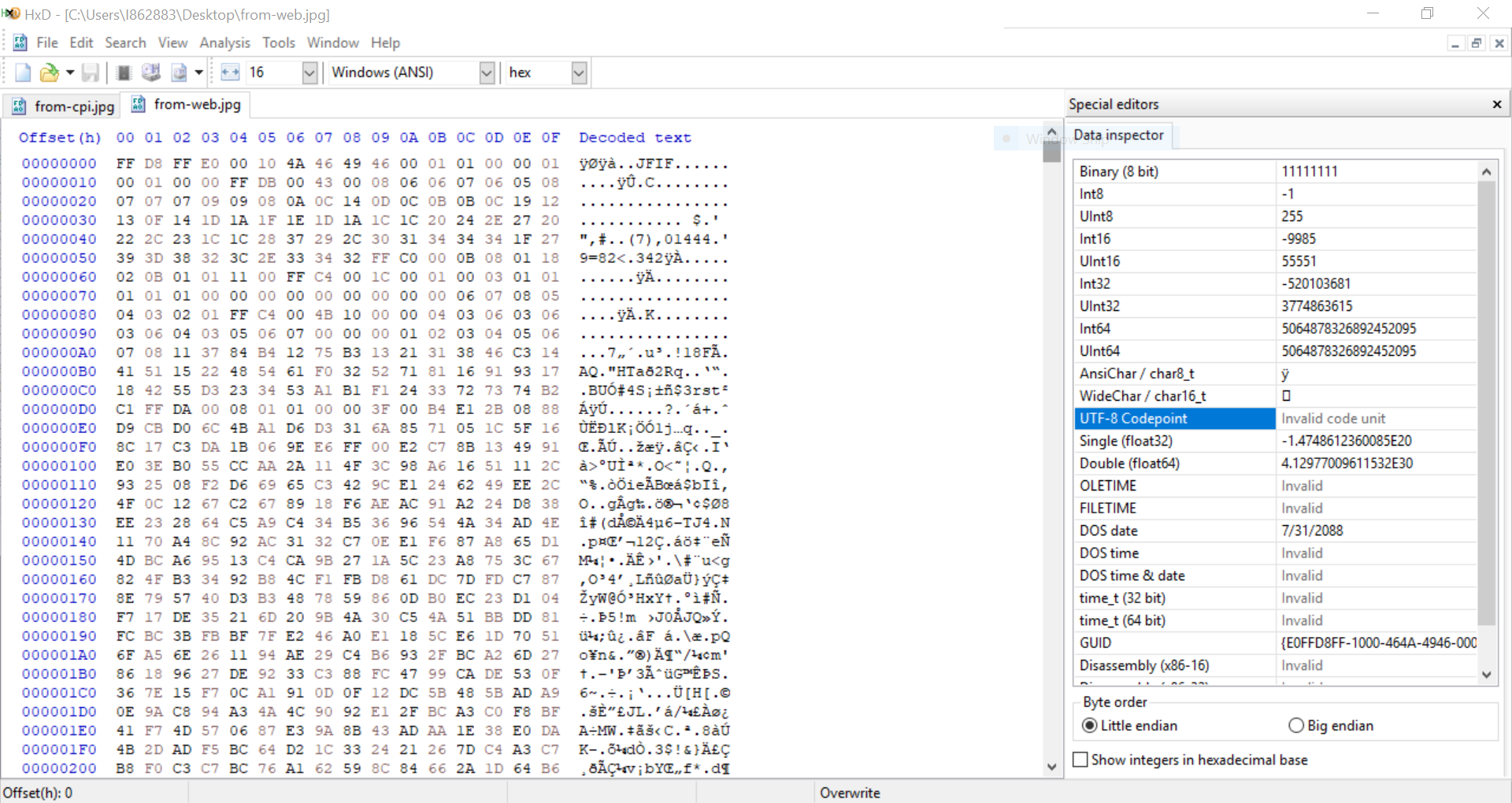
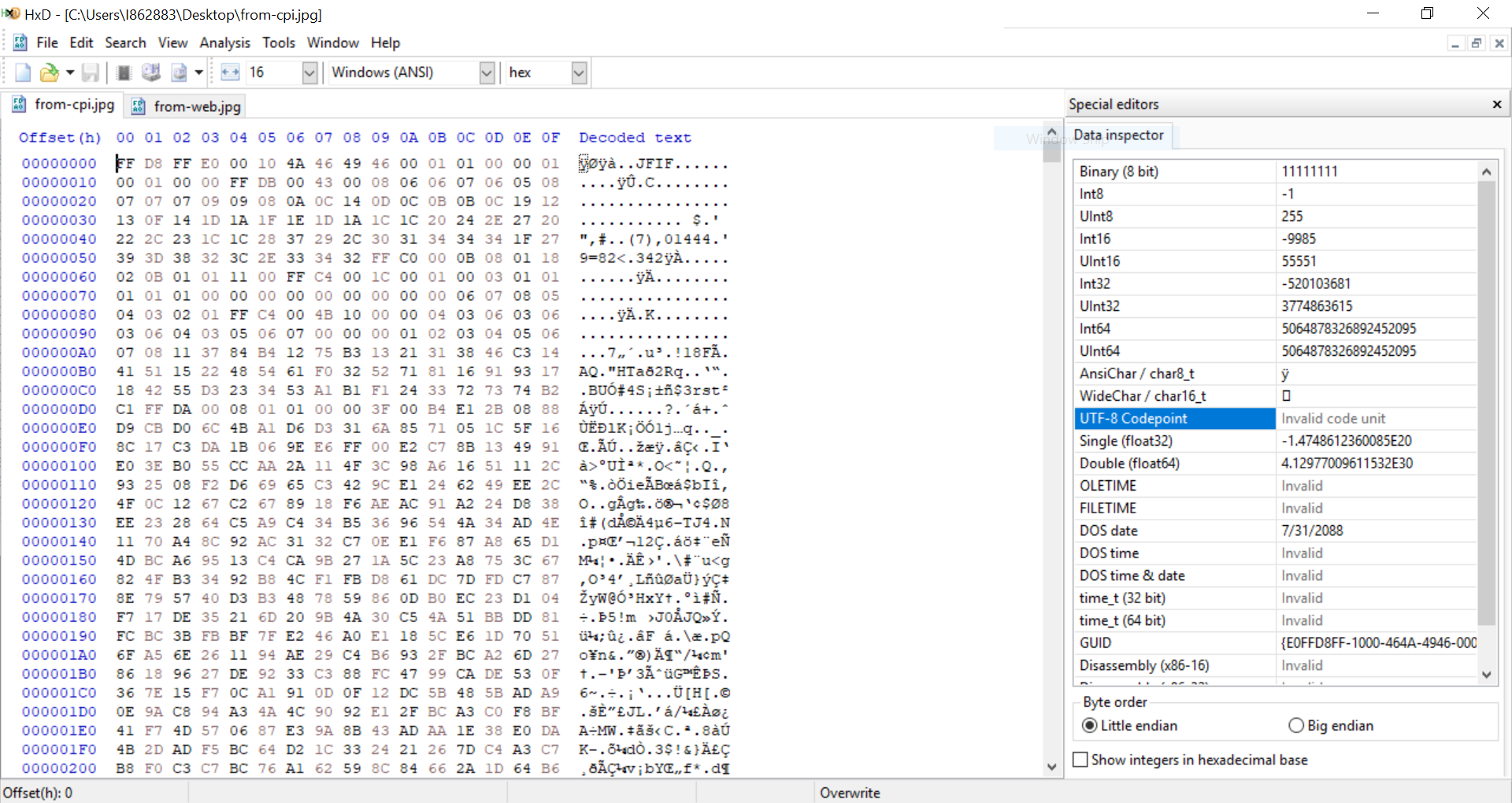
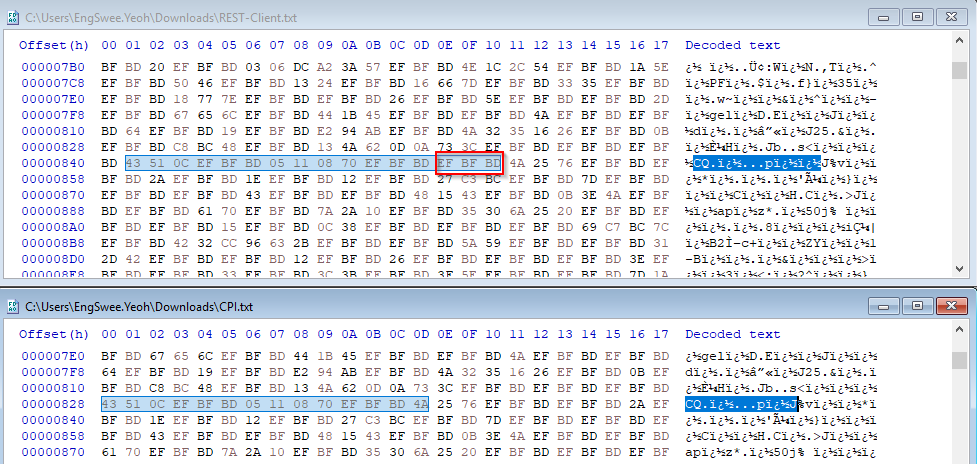
Também notei que ao visualizar a solicitação HTTP bruta feita pela CPI, os dados da imagem são ligeiramente diferentes dos dados da imagem ao enviá-los usando um Cliente REST. Há alguns caracteres faltando de vez em quando na solicitação feita pela CPI.
Aqui estão dois exemplos das solicitações, uma enviada de um Cliente REST, a outra enviada pela CPI. A solicitação do Cliente REST funciona ao ser enviada para a API de OCR, mas a solicitação da CPI não (retorna um erro 500).
Solicitação do Cliente REST
Solicitação da CPI
Novamente, as diferenças são o valor do cabeçalho Content-Length e alguns caracteres faltando na solicitação da CPI.
Aqui estão algumas perguntas:
1. Estou usando uma solicitação-resposta para obter os dados da imagem bruta da maneira correta para armazenar a imagem no corpo da mensagem, ou há um método melhor?
2. Como posso enviar corretamente esta imagem para a API de OCR? Até agora, só tenho recebido erros 500 do servidor da API de OCR.
3. Devo usar um codificador MIME Multipart ou um script para modificar a codificação? Se sim, como?
TL;DR: Quero enviar uma imagem para um API de reconhecimento óptico de caracteres.



{kind=link}
{kind=link}
{kind=link}
{kind=link}