
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPCómo Configurar un Sitio de Desastre para SAP Basis con SAP ASE 16.0: Guía Paso a Paso
- Creado 01/03/2024
- Modificado 01/03/2024
- 47 Vistas
0
Cargando...
Este blog post/Artículo es para todos los niveles de Administradores de Sistemas SAP Basis que deseen configurar una solución simple de Sitio de Desastre (DR) (Activo-Pasivo) para sus Sistemas SAP que se ejecutan con la Base de Datos SAP ASE 16.0 (Sybase) con pasos guiados.
Este blog se centrará en "Cómo Configurar/Implementar", "Cómo reconfigurar", "Cómo Desinstalar" el Sitio de DR basado en la Base de Datos SAP ASE (Sybase).
El proceso descrito aquí establecerá un sitio de DR simple para la base de datos de SAP ASE 16.0 (Sybase) en clúster en la plataforma OS Windows 2012 con/sin Clúster de Fail-over.
Al finalizar la configuración del Sitio de DR como se describe en este artículo, el paisaje del sistema del Sitio Primario y del DR se verá de la siguiente manera:
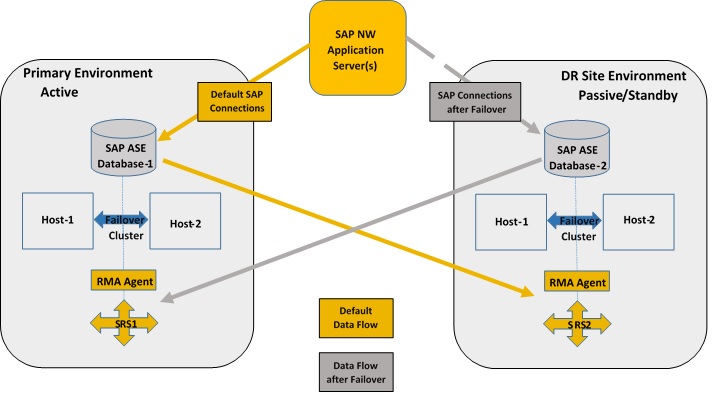
Nota: En la imagen anterior, la Base de Datos SAP ASE 16.0, el Agente RMA, SRS son parte del Clúster de Fail-over de Windows OS en la Configuración Final.
Intentemos entender quiénes serán los principales actores y cómo desempeñarán su papel en toda la configuración. Esta es una parte muy importante porque la ejecución con un entendimiento adecuado se llama buena calidad de Consultor SAP genuino.
Base de Datos Fuente (también llamada base de datos primaria): Una base de datos que es la fuente de datos y transacciones que modifican datos en la base de datos de destino.
Agente de Gestión de Replicación (RMA) (también llamado agente de replicación): Un agente específico de base de datos (dependiendo de la base de datos fuente) que admite la replicación de datos y transacciones desde una base de datos fuente a un servidor de replicación.
Proceso del Servidor de Replicación de Sybase (SRS) : El servidor recibe datos y transacciones replicados de la base de datos fuente a través del agente de replicación y controla su transición a la base de datos de destino.
Base de Datos de Destino (también llamada base de datos compañera/standby/DR site): Una base de datos que es el objetivo de datos y transacciones que se modifican en la base de datos fuente.
Administrador de Clúster de Failover de MS (opcional): Será necesario para proporcionar Alta Disponibilidad a los Componentes de Replicación de Sybase instalados como RMA, SRS
¿Cómo funcionará la configuración?
Este blog se centrará en "Cómo Configurar/Implementar", "Cómo reconfigurar", "Cómo Desinstalar" el Sitio de DR basado en la Base de Datos SAP ASE (Sybase).
El proceso descrito aquí establecerá un sitio de DR simple para la base de datos de SAP ASE 16.0 (Sybase) en clúster en la plataforma OS Windows 2012 con/sin Clúster de Fail-over.
Contenidos:
- Resumen del Proceso/Configuración
- Preparación y Requisitos previos
- Pasos de Instalación
- Pasos Post-Instalación
- Otras Tareas
Resumen del Proceso/Configuración
Al finalizar la configuración del Sitio de DR como se describe en este artículo, el paisaje del sistema del Sitio Primario y del DR se verá de la siguiente manera:
Nota: En la imagen anterior, la Base de Datos SAP ASE 16.0, el Agente RMA, SRS son parte del Clúster de Fail-over de Windows OS en la Configuración Final.
Intentemos entender quiénes serán los principales actores y cómo desempeñarán su papel en toda la configuración. Esta es una parte muy importante porque la ejecución con un entendimiento adecuado se llama buena calidad de Consultor SAP genuino.
Componentes que juegan un papel importante en toda la Configuración:
Base de Datos Fuente (también llamada base de datos primaria): Una base de datos que es la fuente de datos y transacciones que modifican datos en la base de datos de destino.
Agente de Gestión de Replicación (RMA) (también llamado agente de replicación): Un agente específico de base de datos (dependiendo de la base de datos fuente) que admite la replicación de datos y transacciones desde una base de datos fuente a un servidor de replicación.
Proceso del Servidor de Replicación de Sybase (SRS) : El servidor recibe datos y transacciones replicados de la base de datos fuente a través del agente de replicación y controla su transición a la base de datos de destino.
Base de Datos de Destino (también llamada base de datos compañera/standby/DR site): Una base de datos que es el objetivo de datos y transacciones que se modifican en la base de datos fuente.
Administrador de Clúster de Failover de MS (opcional): Será necesario para proporcionar Alta Disponibilidad a los Componentes de Replicación de Sybase instalados como RMA, SRS
¿Cómo funcionará la configuración?
Veamos una breve descripción general sin entrar en muchos detalles.
- Durante la carga inicial y la replicación, el agente de replicación (RMA) lee el registro de transacciones de la base de datos fuente y genera la Salida de Lenguaje de Transferencia de Registro (LTL), que es una notación (usando un lenguaje) que el servidor de replicación (SRS) utiliza para procesar datos identificados y recopilados a lo largo del canal de replicación de la fuente a la base de datos de destino.
- El servidor de replicación primario (SRS) recibe el LTL de un agente de replicación y envía los datos replicados al servidor de replicación compañero (Standby/DR Site) (cuando se utiliza una separación entre el servidor de replicación primario y el servidor de replicación replicado). De lo contrario, el envío no se realiza porque los datos son operados por una única instancia de servidor de replicación). El servidor de replicación compañero convierte los datos recibidos del LTL al formato y lenguaje nativos utilizados por la base de datos de destino. Envía los datos replicados a la base de datos de destino para su procesamiento, lo que cierra el proceso de replicación (si se confirma en la base de datos de destino).
- Por razones de consistencia de datos (sin pérdida de datos), cada servidor de replicación utiliza una base de datos llamada Base de Datos del Sistema del Servidor de Replicación (RSSD) para almacenar datos de replicación y metadatos. Esta información puede ser utilizada por un agente de replicación para proporcionar funciones avanzadas
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2025 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?