
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPCómo abordar los desafíos de los científicos de datos con SAP HANA: Una guía completa
- Creado 01/03/2024
- Modificado 01/03/2024
- 17 Vistas
0
Cargando...
Introducción
Este es el cuarto de 5 publicaciones de blog que forman parte de la serie "SAP BTP Data & Analytics Showcase". Te recomiendo que consultes nuestra publicación general para tener una mejor comprensión del escenario de extremo a extremo, que involucra múltiples soluciones de base de datos y análisis de SAP HANA en la nube.
Hoy en día, experimentamos y hablamos mucho sobre inteligencia artificial, aprendizaje automático, análisis predictivo y ciencia de datos tanto en nuestra vida diaria como en los negocios. Expertos como los científicos de datos desempeñan un papel esencial en la implementación de casos de uso de datos y análisis de valor agregado para las empresas. Sin embargo, los científicos de datos todavía enfrentan algunos desafíos que dificultan su capacidad para trabajar de manera efectiva y derivar valor comercial de los datos en entornos del mundo real. Puedes consultar la publicación de blog de una destacada experta en ciencia de datos de SAP y obtener más información desde su perspectiva.
Para demostrar cómo nuestras soluciones unificadas de datos y análisis de SAP HANA abordan algunos desafíos de los científicos de datos y ayudan en su trabajo diario de manera integral, con flexibilidad, me motiva a crear esta publicación de blog.
En las secciones próximas de este blog, me gustaría resaltar cómo los científicos de datos pueden elegir las soluciones que desean, combinar capacidades de nuestro portafolio y resolver un problema específico de extremo a extremo:
- Preparación de datos - Para cerrar la brecha entre los científicos de datos y TI, recomendamos que los científicos de datos puedan estar involucrados desde temprano en la fase de integración y preparación de datos. Se ofrece un único lugar (SAP Data Warehouse Cloud) para combinar todos los datos necesarios de diferentes fuentes, en todo el panorama de TI real de la empresa.
- Creación de modelos - El código abierto (por ejemplo, Python o R) es un pilar importante de los proyectos de ciencia de datos. Los científicos de datos pueden seguir utilizando scripts de Python en Jupyter Notebook, donde se ha establecido la conexión con los artefactos de SAP Data Warehouse Cloud, y entrenar modelos de ML.
- Inferencia de modelos - Los modelos de ML entrenados se reutilizan para hacer una predicción. Los resultados de la predicción se escriben fácilmente de vuelta a SAP Data Warehouse Cloud (a través de un esquema llamado Open SQL Schema), que luego se puede consumir para mejorar tus modelos de datos.
- Visualización de resultados - Como último paso, para mostrar hallazgos/patrones detrás de los datos de una manera consumible, por ejemplo, a los usuarios comerciales, se crea o se mejora un panel agradable que combina resultados predictivos mediante herramientas de autoservicio en SAP Analytics Cloud.
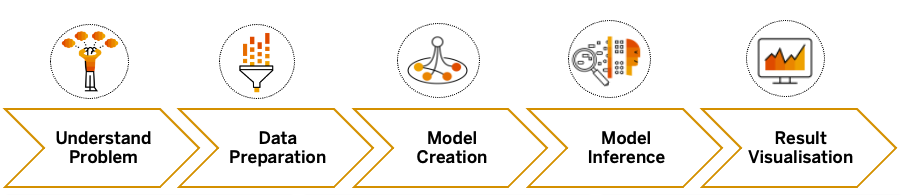
Figura 1: Escenario de Ciencia de Datos de Extremo a Extremo
...
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2025 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?