


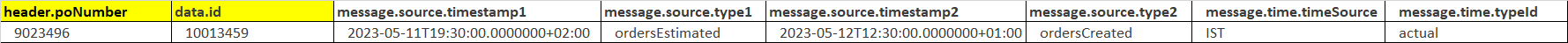
{kind=link}
0
Cargando...
vitaliy.rudnytskiy
Aqui estão os dados enviados para o operador Python 3 como uma string JSON. Isso precisa ser filtrado e depois atualizado na tabela do banco de dados sem colunas duplicadas.
poNumber e id são chaves primárias/identificadores únicos em cada linha. Obrigado!
{
"header":{
"poNumber":"9023496"
},
"data":{
"id":"10013459"
},
"message":{
"source":[
{
"createSource":null,
"timeStamp":"2023-05-12T19:30:00.0000000+02:00",
"type":"full"
},
{
"createSource":"testdev",
"timeStamp":"2023-05-11T19:30:00.0000000+02:00",
"type":"ordersEstimated"
},
{
"createSource":"event",
"timeStamp":"2023-05-12T12:30:00.0000000+01:00",
"type":"ordersCreated"
}
],
"time":[
{
"timeSource":"UTC",
"typeId":"full"
},
{
"timeSource":"IST",
"typeId":"actual"
}
]
}
}
Respondido el 15/04/2024
LUCIANO RIOJA GHIOTTO
Se unió el 13/07/2019
{kind=link}