
Aprende en Comunidad
Avalados por :


Integrando Aprendizado de Máquina com o SAP BW/4HANA para Insights Aprimorados Baseados em Dados.
- Creado 01/03/2024
- Modificado 01/03/2024
- 2 Vistas
0
Cargando...
Machine Learning no SAP HANA é uma ótima coisa. Com as duas bibliotecas de Machine Learning integradas (
PAL
e
APL
) para escolher, que suportam todas as tarefas principais de Machine Learning, você está mais do que bem equipado para construir soluções inteligentes baseadas em dados no SAP HANA.
Agora, o Machine Learning no SAP HANA se torna ainda melhor quando combinado com um aplicativo. Somente assim, insights baseados em dados podem ser integrados e aproveitados onde são mais necessários - como parte dos processos de negócios. Enquanto o SAP S/4HANA oferece uma grande seleção de cenários inteligentes predefinidos e fornece um conjunto padrão de ferramentas para aprimoramentos personalizados de Machine Learning ( LINK ), os clientes do SAP BW/4HANA às vezes têm dificuldades para iniciar iniciativas de Machine Learning em cima de seu Data Warehouse existente.
Meu colega tobiaswohkittel e eu unimos forças para ajudar a superar essas dificuldades. Com este post no blog, pretendemos fornecer orientações específicas sobre como o Machine Learning pode ser facilmente integrado aos artefatos principais do SAP BW, aproveitando todas as ferramentas padrão fornecidas com o SAP BW/4HANA. A integração será o foco deste artigo e manteremos a parte de Machine Learning muito simples e baseada em valores padrão.
Você pode encontrar todos os nossos artefatos de desenvolvimento, incluindo os dados de exemplo, nosso notebook Jupyter e os trechos de código ABAP em nosso repositório GitHub de amostras . É baseado em um SAP BW/4 2.0, que roda no ABAP Foundation 7.53 e no SAP HANA SP05, e nossa versão da API Python é 2.11.22010700.
Vamos voltar por um momento e ver o que estamos prestes a fazer especificamente.
O Machine Learning tem 2 processos principais: Treinar um modelo e aplicar um modelo para receber previsões (frequentemente referidas como Inferência ). Vamos trazer ambos à vida aqui. Ao fazer isso, nosso objetivo é ficar o mais próximo possível dos padrões do SAP BW com o mínimo de codificação personalizada. O SAP BW possui vários objetos e ferramentas de modelagem excelentes que utilizaremos para isso:
O Objeto de Armazenamento de Dados Avançado (aDSO) é o objeto padrão de armazenamento de dados, comparável a uma tabela de banco de dados. Uma Transformação define regras a serem executadas contra esses dados ao movê-los entre dois aDSOs. Um Processo de Transferência de Dados (DTP) nos ajuda a acionar essas Transformações. E, por fim, há o ABAP como nossa linguagem de script nativa e, especificamente, Procedimentos de Banco de Dados Gerenciados ABAP (AMDPs) , que constroem a ponte entre o ABAP e o SAP HANA, envolvendo SQLScript em código ABAP. Você encontrará todos eles na visão geral abaixo de nossa arquitetura alvo.
Agora, se você tem um pouco de experiência com o SAP BW, esse esquema pode parecer estranho para você. Em cenários típicos de Data Warehousing e cargas de trabalho ETL, uma Transformação aplicaria apenas pequenas alterações aos dados, realizando cálculos, operações de string, conversões e similares. Aqui, a entrada e saída da Transformação parecem estar completamente desconectadas, mas no final, o Machine Learning é de fato apenas uma transformação muito complexa de dados e a boa notícia é: funciona muito bem e nos ajuda a permanecer dentro das ferramentas padrão.
Com esse plano todo delineado, estamos prontos para dar uma olhada no sistema real agora.
Para esta demonstração, usaremos alguns dados salariais inventados e preveremos o nível de emprego correspondente a um funcionário, com base em alguns dados demográficos e de emprego. A imagem abaixo mostra um extrato desses dados.
A partir daqui, aproveitaremos a integração estreita entre o SAP HANA e o SAP BW/4HANA, que permite que nosso Cientista de Dados trabalhe com recursos nativos no SAP HANA, bem como Python, enquanto nosso especialista em SAP BW mantém todas as estruturas com ferramentas padrão do SAP BW.
Para simular um cenário de relatório padrão, o Cientista de Dados só tem acesso a uma consulta baseada nos dados de treinamento em vez da tabela de dados bruta. Essa consulta se traduz automaticamente em uma Visualização de Cálculo do SAP HANA que pode ser acessada usando o cliente Python para Machine Learning do SAP HANA. Assim, experimentar e trabalhar com os dados do SAP BW parece natural para o Cientista de Dados. Como nossa variável alvo
Agora, o Machine Learning no SAP HANA se torna ainda melhor quando combinado com um aplicativo. Somente assim, insights baseados em dados podem ser integrados e aproveitados onde são mais necessários - como parte dos processos de negócios. Enquanto o SAP S/4HANA oferece uma grande seleção de cenários inteligentes predefinidos e fornece um conjunto padrão de ferramentas para aprimoramentos personalizados de Machine Learning ( LINK ), os clientes do SAP BW/4HANA às vezes têm dificuldades para iniciar iniciativas de Machine Learning em cima de seu Data Warehouse existente.
Meu colega tobiaswohkittel e eu unimos forças para ajudar a superar essas dificuldades. Com este post no blog, pretendemos fornecer orientações específicas sobre como o Machine Learning pode ser facilmente integrado aos artefatos principais do SAP BW, aproveitando todas as ferramentas padrão fornecidas com o SAP BW/4HANA. A integração será o foco deste artigo e manteremos a parte de Machine Learning muito simples e baseada em valores padrão.
Você pode encontrar todos os nossos artefatos de desenvolvimento, incluindo os dados de exemplo, nosso notebook Jupyter e os trechos de código ABAP em nosso repositório GitHub de amostras . É baseado em um SAP BW/4 2.0, que roda no ABAP Foundation 7.53 e no SAP HANA SP05, e nossa versão da API Python é 2.11.22010700.
O Plano
Vamos voltar por um momento e ver o que estamos prestes a fazer especificamente.
O Machine Learning tem 2 processos principais: Treinar um modelo e aplicar um modelo para receber previsões (frequentemente referidas como Inferência ). Vamos trazer ambos à vida aqui. Ao fazer isso, nosso objetivo é ficar o mais próximo possível dos padrões do SAP BW com o mínimo de codificação personalizada. O SAP BW possui vários objetos e ferramentas de modelagem excelentes que utilizaremos para isso:
O Objeto de Armazenamento de Dados Avançado (aDSO) é o objeto padrão de armazenamento de dados, comparável a uma tabela de banco de dados. Uma Transformação define regras a serem executadas contra esses dados ao movê-los entre dois aDSOs. Um Processo de Transferência de Dados (DTP) nos ajuda a acionar essas Transformações. E, por fim, há o ABAP como nossa linguagem de script nativa e, especificamente, Procedimentos de Banco de Dados Gerenciados ABAP (AMDPs) , que constroem a ponte entre o ABAP e o SAP HANA, envolvendo SQLScript em código ABAP. Você encontrará todos eles na visão geral abaixo de nossa arquitetura alvo.
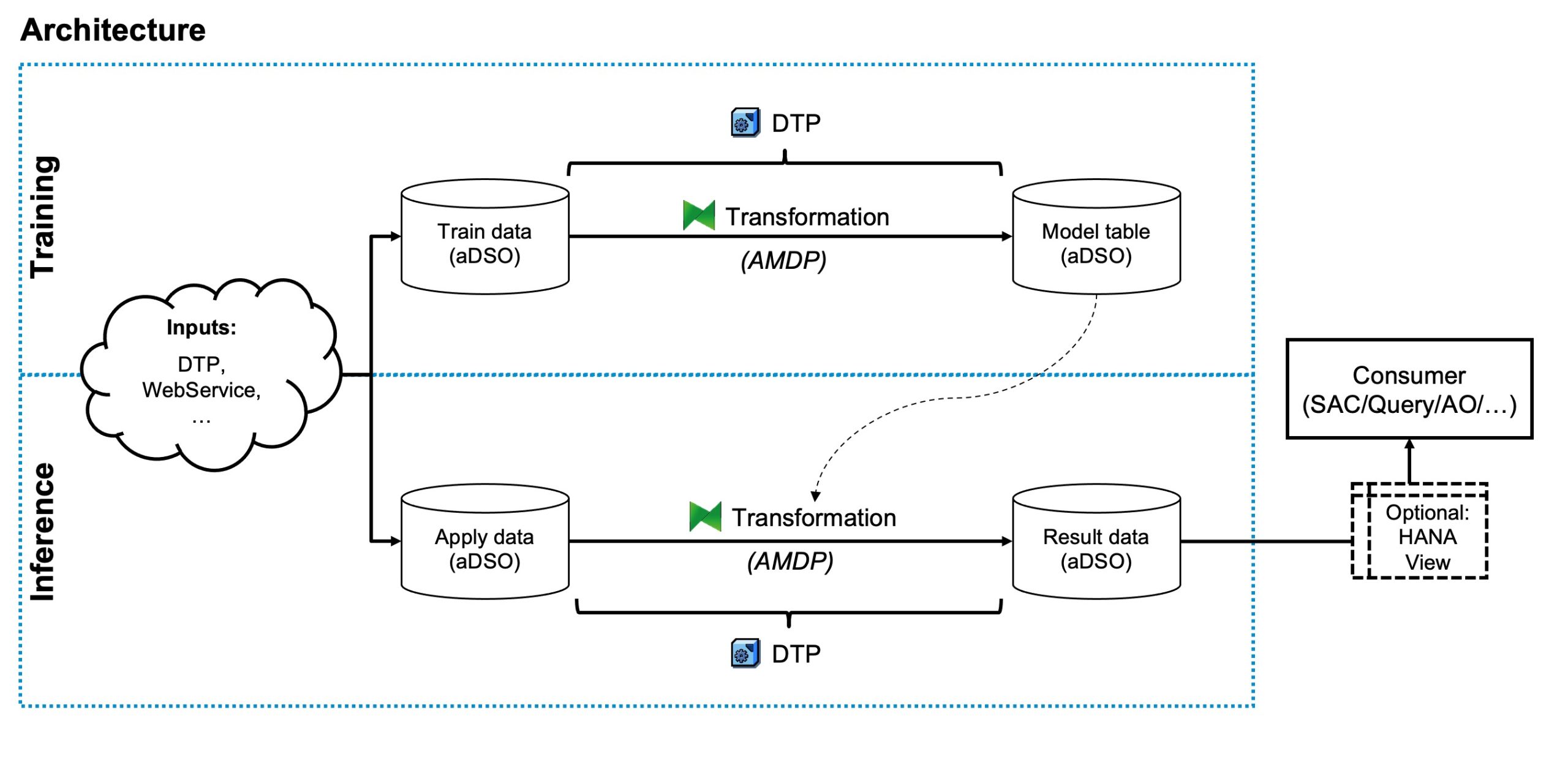 Ao olhar para a imagem, você verá que o treinamento e a inferência do modelo se parecem muito e seguem o mesmo esquema:
Ao olhar para a imagem, você verá que o treinamento e a inferência do modelo se parecem muito e seguem o mesmo esquema:
- Um aDSO armazenando nossos dados de entrada
- Uma Transformação que lida com o treinamento ou a inferência do modelo
- Um DTP para acionar a carga de dados entre nosso aDSO de origem e destino
- Um aDSO que recebe os resultados, seja o modelo treinado ou as previsões derivadas
Agora, se você tem um pouco de experiência com o SAP BW, esse esquema pode parecer estranho para você. Em cenários típicos de Data Warehousing e cargas de trabalho ETL, uma Transformação aplicaria apenas pequenas alterações aos dados, realizando cálculos, operações de string, conversões e similares. Aqui, a entrada e saída da Transformação parecem estar completamente desconectadas, mas no final, o Machine Learning é de fato apenas uma transformação muito complexa de dados e a boa notícia é: funciona muito bem e nos ajuda a permanecer dentro das ferramentas padrão.
Com esse plano todo delineado, estamos prontos para dar uma olhada no sistema real agora.
Implementação
Para esta demonstração, usaremos alguns dados salariais inventados e preveremos o nível de emprego correspondente a um funcionário, com base em alguns dados demográficos e de emprego. A imagem abaixo mostra um extrato desses dados.

A partir daqui, aproveitaremos a integração estreita entre o SAP HANA e o SAP BW/4HANA, que permite que nosso Cientista de Dados trabalhe com recursos nativos no SAP HANA, bem como Python, enquanto nosso especialista em SAP BW mantém todas as estruturas com ferramentas padrão do SAP BW.
Para simular um cenário de relatório padrão, o Cientista de Dados só tem acesso a uma consulta baseada nos dados de treinamento em vez da tabela de dados bruta. Essa consulta se traduz automaticamente em uma Visualização de Cálculo do SAP HANA que pode ser acessada usando o cliente Python para Machine Learning do SAP HANA. Assim, experimentar e trabalhar com os dados do SAP BW parece natural para o Cientista de Dados. Como nossa variável alvo
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
contacto@primeinstitute.com
(+51) 1641 9379
(+57) 1489 6964
© 2024 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?