
Aprende en Comunidad
Avalados por :


Implementação de detecção de objetos personalizada com YOLO e SAP Leonardo Machine Learning Foundation: Guia passo a passo
- Creado 01/03/2024
- Modificado 01/03/2024
- 9 Vistas
0
Cargando...
Em meu blog anterior, vimos como a Detecção de Objetos com tensorflow e yolo é aplicada em um contexto empresarial em conjunto com a SAP Leonardo Machine Learning Foundation. Agora veremos como implementar a detecção de objetos personalizada com yolo para criar soluções inteligentes, especialmente como treinar um detector de objetos personalizado com um conjunto de dados personalizado e disponibilizá-lo como uma API RESTful na SAP Cloud Platform, Cloud Foundry, sendo consumido por sua solução inteligente por meio de HTTP(s) desacoplado.
Minha série de blogs sobre Detecção de Objetos para a Empresa Inteligente:
You Only Look Once (YOLO) é um sistema de detecção de objetos em tempo real de última geração. Confira este vídeo inspirador sobre como os computadores aprendem a reconhecer objetos instantaneamente por Joseph Redmon no TED talk. Assim como este vídeo introdutório sobre o algoritmo YOLO por Adrew Ng.
Para mais detalhes sobre YOLO, você pode consultar seu site oficial.
Para treinar seu próprio detector de objetos, você precisa preparar o conjunto de dados para o treinamento, incluindo imagens com os objetos-alvo e rotulando o objeto nas imagens. Aqui está meu conjunto de dados de sapatos pronto para uso (incluindo imagens e arquivos de etiquetas de yolo) para um início rápido, onde você pode pular as etapas 1 e 2.
Em meu caso, precisamos detectar sapatos na Solução de Mercado SMB para uma experiência de compra online inteligente ao encontrar um sapato correspondente a uma foto via Facebook Messenger. Então, eu preciso de um conjunto de dados de imagens de sapatos, que posso encontrar facilmente no Google buscando por imagens de "sapatos".
Para baixar as imagens em massa, usei uma extensão do Google Chrome chamada Fatkun Batch Download Image.
Minha série de blogs sobre Detecção de Objetos para a Empresa Inteligente:
- Detecção de Objetos pronta para uso para a Empresa Inteligente
- Detecção de Objetos com Tensorflow para a Empresa Inteligente
- Detecção de Objetos com YOLO para a Empresa Inteligente (este blog)
Resumo da Detecção de Objetos YOLO
You Only Look Once (YOLO) é um sistema de detecção de objetos em tempo real de última geração. Confira este vídeo inspirador sobre como os computadores aprendem a reconhecer objetos instantaneamente por Joseph Redmon no TED talk. Assim como este vídeo introdutório sobre o algoritmo YOLO por Adrew Ng.
Para mais detalhes sobre YOLO, você pode consultar seu site oficial.
Treinando um detector de objetos personalizado com YOLO
1. Preparar o Conjunto de Dados
Para treinar seu próprio detector de objetos, você precisa preparar o conjunto de dados para o treinamento, incluindo imagens com os objetos-alvo e rotulando o objeto nas imagens. Aqui está meu conjunto de dados de sapatos pronto para uso (incluindo imagens e arquivos de etiquetas de yolo) para um início rápido, onde você pode pular as etapas 1 e 2.
Passo 1: Baixar Imagens com Objetos-Alvo
Em meu caso, precisamos detectar sapatos na Solução de Mercado SMB para uma experiência de compra online inteligente ao encontrar um sapato correspondente a uma foto via Facebook Messenger. Então, eu preciso de um conjunto de dados de imagens de sapatos, que posso encontrar facilmente no Google buscando por imagens de "sapatos".
Para baixar as imagens em massa, usei uma extensão do Google Chrome chamada Fatkun Batch Download Image.
- Desmarque as imagens sem sapatos e as imagens de papelão (não no formato JPG) dos resultados da pesquisa do Google.
-
Clique no botão Mais Opções para renomear a imagem com o formato "sapatos_{NO000}.JPEG" conforme mostrado na tela, o que salvará a imagem como shoes_000.JPEG~shoe_999.JPEG
Algumas dicas:
1). Salve a imagem em um formato adequado. No meu caso, o formato JPEG é necessário pela ferramenta de anotação (no meu caso) posteriormente.
2). Quanto mais próximas as imagens (ângulo, fundo, etc.) no conjunto de dados de treinamento estiverem da imagem real de entrada em seu caso, mais precisos serão os resultados da detecção.
3). Pode ser necessário de 300 a 600 imagens por classe para obter um resultado de detecção relativamente muito bom conforme esperado. Pode exigir mais imagens de diferentes ângulos e fundos para ter uma detecção quase perfeita. No meu caso, tenho 600 imagens baixadas (540 para treinamento, 60 para testes).
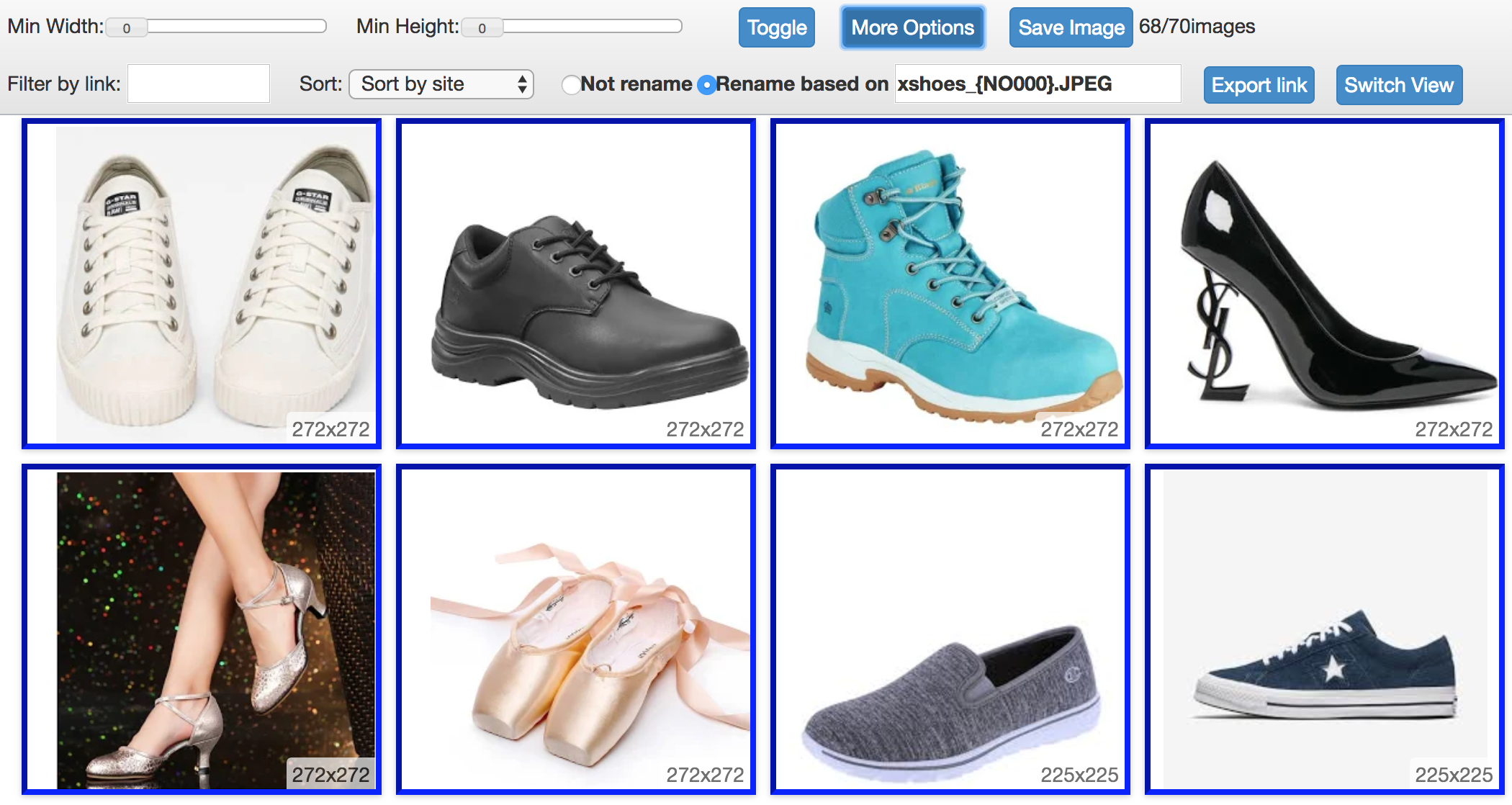
- Clique no botão Salvar imagem e então terá as imagens baixadas. Vamos renomear a pasta de imagens como "conjunto de dados".
Passo 2: Rotular as Imagens com os Objetos
Pedro Pascal
Se unió el 07/03/2018
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
contacto@primeinstitute.com
(+51) 1641 9379
(+57) 1489 6964
© 2025 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute