
Aprende en Comunidad
Avalados por :


Gerenciamento de dados VARCHAR e NVARCHAR no SAP Hana: Erros comuns e recomendações
- Creado 01/03/2024
- Modificado 01/03/2024
- 12 Vistas
0
Cargando...
Ayer tuve una discusión sobre los tipos de datos VARCHAR y NVARCHAR y su manejo en Hana. A primera vista todo está claro: usar VARCHAR solo para caracteres ASCII (inglés), todo lo demás debe usar NVARCHAR. La pregunta fue ¿qué sucede cuando se utiliza VARCHAR por accidente?
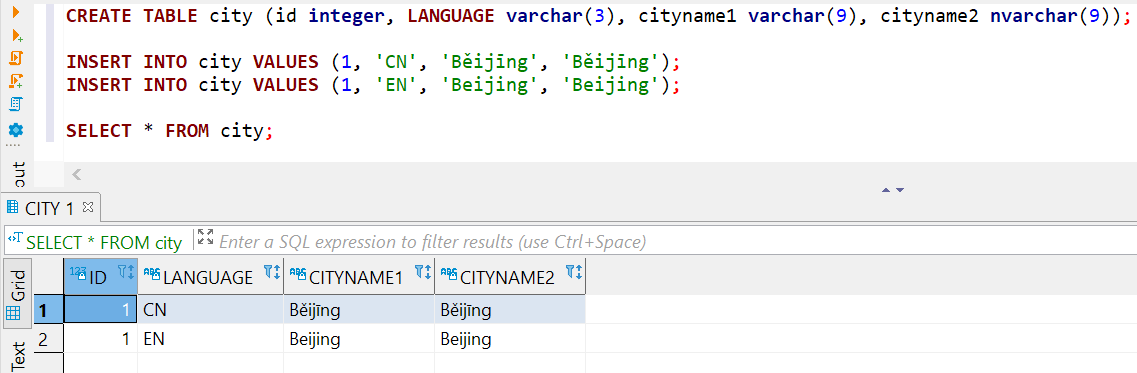
Aquí un ejemplo: Creo una tabla, inserto dos filas, selecciono de ella y todo parece estar perfectamente bien.
La primera indicación de que hay diferencias en realidad es cuando agrego otra ciudad que tiene 8 caracteres de longitud. Aquí obtengo un error:
El error está en CITYNAME1, la columna varchar(9). La razón es obvia, ya que el manual de Hana establece que el tipo de datos VARCHAR es solo para caracteres ASCII de 7 bits, pero nuestro texto tiene algunos caracteres no ASCII.
Cuando intento insertar la cadena de 8 caracteres 'Shenzhèn', sus bytes(!) se insertan y debido a los dos caracteres de doble byte, la matriz de bytes tiene una longitud de 10 bytes. No cabe en un VARCHAR(9).
La representación UTF-8 de ese nombre de ciudad es
Eso plantea dos preguntas interesantes para el caso de Beijing:
Para la primera pregunta argumentaría que sí, debería. Actualmente el enfoque es que un texto se envía a la base de datos y se insertan sus bytes. No se aplica lógica ni pruebas. El texto simplemente se trata como un array de números binarios.
Y eso responde también a la segunda pregunta. Los datos binarios se leen de la base de datos como un flujo de bytes y la mayoría de las herramientas usan el convertidor UTF-8 predeterminado para mostrar el texto, por lo que el texto parece ser correcto. Pero no hay garantía de eso. Otras herramientas mostrarán el texto como una lista de caracteres ASCII y devolverán "BÄ ijÄ«ng" en lugar de "Beijing".
En otras palabras, al insertar el texto "Beijing" en un VARCHAR y seleccionar el valor con la misma herramienta, se comete el mismo error dos veces: convertir texto a binario y binario a texto con la misma conversión, y por lo tanto se anulan entre sí, todo parece estar bien. Pero eso es pura suerte. Otra herramienta podría usar otro conjunto de caracteres predeterminado, especialmente las herramientas nativas de Windows.
Realmente deberías almacenar caracteres ASCII solo en VARCHAR y usar NVARCHAR para todo lo demás.
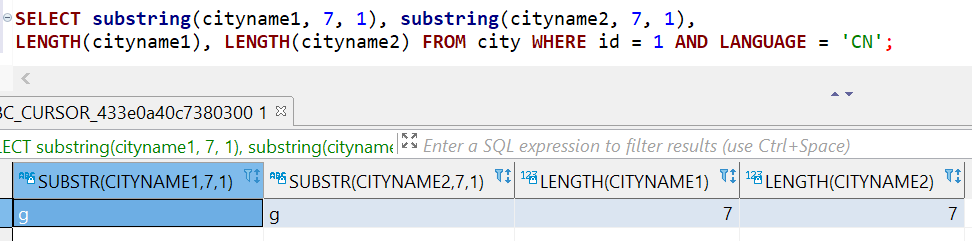
No ayuda que todas las funciones internas de Hana como length(), substring(), etc. también estén utilizando los valores UTF-8. Para la función length el manual de Hana lo establece explícitamente, para la función substring no lo hace. Dado que UTF-8 y ASCII son idénticos para todos los caracteres del 0 al 127 (7 bits), no se necesita un manejo especial si VARCHAR contiene solo valores ASCII de 7 bits. Pero si no lo hace, estamos en un estado indefinido.
Aquí un ejemplo: Creo una tabla, inserto dos filas, selecciono de ella y todo parece estar perfectamente bien.
La primera indicación de que hay diferencias en realidad es cuando agrego otra ciudad que tiene 8 caracteres de longitud. Aquí obtengo un error:
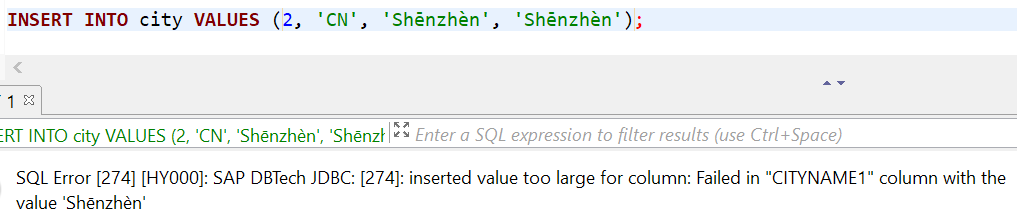
El error está en CITYNAME1, la columna varchar(9). La razón es obvia, ya que el manual de Hana establece que el tipo de datos VARCHAR es solo para caracteres ASCII de 7 bits, pero nuestro texto tiene algunos caracteres no ASCII.
Cuando intento insertar la cadena de 8 caracteres 'Shenzhèn', sus bytes(!) se insertan y debido a los dos caracteres de doble byte, la matriz de bytes tiene una longitud de 10 bytes. No cabe en un VARCHAR(9).
La representación UTF-8 de ese nombre de ciudad es
S | h | e | n | z | h | è | n
53 | 68 | c4 93 | 6e | 7a | 68 | c3 a8 | 6nEso plantea dos preguntas interesantes para el caso de Beijing:
- ¿Por qué funciona la primera inserción aunque estemos insertando caracteres no ASCII en varchar? ¿No debería generar un error como "¡Oye, eso no es una cadena ASCII!"?
- ¿Por qué la selección devuelve el texto correcto aunque se lea de un tipo de datos que no puede manejarlo?
Para la primera pregunta argumentaría que sí, debería. Actualmente el enfoque es que un texto se envía a la base de datos y se insertan sus bytes. No se aplica lógica ni pruebas. El texto simplemente se trata como un array de números binarios.
Y eso responde también a la segunda pregunta. Los datos binarios se leen de la base de datos como un flujo de bytes y la mayoría de las herramientas usan el convertidor UTF-8 predeterminado para mostrar el texto, por lo que el texto parece ser correcto. Pero no hay garantía de eso. Otras herramientas mostrarán el texto como una lista de caracteres ASCII y devolverán "BÄ ijÄ«ng" en lugar de "Beijing".
En otras palabras, al insertar el texto "Beijing" en un VARCHAR y seleccionar el valor con la misma herramienta, se comete el mismo error dos veces: convertir texto a binario y binario a texto con la misma conversión, y por lo tanto se anulan entre sí, todo parece estar bien. Pero eso es pura suerte. Otra herramienta podría usar otro conjunto de caracteres predeterminado, especialmente las herramientas nativas de Windows.
Realmente deberías almacenar caracteres ASCII solo en VARCHAR y usar NVARCHAR para todo lo demás.
No ayuda que todas las funciones internas de Hana como length(), substring(), etc. también estén utilizando los valores UTF-8. Para la función length el manual de Hana lo establece explícitamente, para la función substring no lo hace. Dado que UTF-8 y ASCII son idénticos para todos los caracteres del 0 al 127 (7 bits), no se necesita un manejo especial si VARCHAR contiene solo valores ASCII de 7 bits. Pero si no lo hace, estamos en un estado indefinido.
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
contacto@primeinstitute.com
(+51) 1641 9379
(+57) 1489 6964
© 2024 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?