
Aprende en Comunidad
Avalados por :


¡Acceso SAP S/4HANA desde $100!
Acceso a SAPExplorando a Arquitetura e Funcionamento do SAP HANA Sidecar: Tudo o que você precisa saber.
- Creado 01/03/2024
- Modificado 01/03/2024
- 67 Vistas
0
Cargando...
Introdução:
O que vem à sua mente quando você ouve a palavra Sidecar? Sim, você está correto: um veículo anexado ao lado de uma motocicleta ou outro veículo para um passageiro, parece interessante!
O mesmo conceito pode ser correlacionado em termos técnicos como é definido a seguir:
SAP HANA Sidecar não é mais do que uma plataforma SAP HANA que serve como um banco de dados secundário a um sistema SAP existente com seu próprio banco de dados tradicional.
Nota: O Banco de Dados Secundário do SAP HANA também é conhecido como Sidecar do SAP HANA, onde o SAP HANA é seu banco de dados, como o nome sugere.
Arquitetura do Sidecar do SAP HANA:
Nota: O Banco de Dados Tradicional pode ser Oracle, MySQL MaxDB, IBM DB2 e muitos mais.
Qual era a necessidade?
Como isso funciona?
Como isso pode ser alcançado?
Conclusão:
O que vem à sua mente quando você ouve a palavra Sidecar? Sim, você está correto: um veículo anexado ao lado de uma motocicleta ou outro veículo para um passageiro, parece interessante!
O mesmo conceito pode ser correlacionado em termos técnicos como é definido a seguir:
SAP HANA Sidecar não é mais do que uma plataforma SAP HANA que serve como um banco de dados secundário a um sistema SAP existente com seu próprio banco de dados tradicional.
Nota: O Banco de Dados Secundário do SAP HANA também é conhecido como Sidecar do SAP HANA, onde o SAP HANA é seu banco de dados, como o nome sugere.
Arquitetura do Sidecar do SAP HANA:
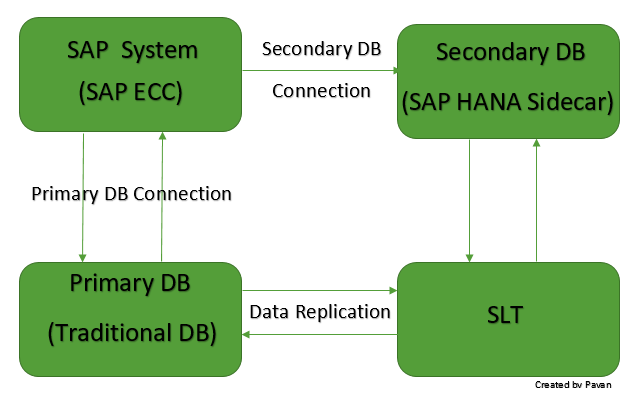
Fig.1.0
Nota: O Banco de Dados Tradicional pode ser Oracle, MySQL MaxDB, IBM DB2 e muitos mais.
Qual era a necessidade?
- Digamos que você tenha alguns programas/relatórios/transações ou objetos que estão demorando muito no Banco de Dados Tradicional (Primário), exceto esses objetos, seu sistema é estável e funciona muito bem. No entanto, você não deseja executar todos os outros relatórios, transações, etc., no banco de dados SAP HANA, pois eles não estão causando problemas.
- Portanto, você precisa que esse conjunto de programas/relatórios/transações ou objetos seja executado no Banco de Dados SAP HANA, pois estão demorando muito mesmo após aplicar todos os tipos de técnicas de ajuste de desempenho.
- Isso se deve basicamente à limitação do Banco de Dados que não é SAP HANA.
- Como todos sabemos, a implementação do SAP HANA impulsiona um negócio com uma velocidade aproximadamente 3600 vezes maior do que a dos bancos de dados tradicionais.
- Portanto, se você deseja acelerar todos esses programas/relatórios/transações ou objetos que levam mais tempo para serem executados, uma das opções para fazê-los funcionar de forma eficiente é usar o SAP HANA como um Banco de Dados Secundário (Sidecar).
Como isso funciona?
- Digamos que você tenha um relatório/qualquer objeto que é muito lento e precisa que funcione de forma eficiente ou seja executado rapidamente. O que você faz?
- Para esse relatório/objeto que é muito lento em termos de execução, você precisa identificar todas as tabelas de banco de dados usadas nesse relatório/objeto e depois de identificá-las, agora sabe que há 5 tabelas de banco de dados usadas nesse relatório/objeto.
- Essas 5 tabelas de banco de dados estão disponíveis no Banco de Dados Tradicional (Primário) e os dados dessas 5 tabelas de banco de dados são armazenados no Banco de Dados Tradicional (Primário).
- Portanto, os dados apenas dessas 5 tabelas de banco de dados são replicados usando o servidor SLT (Transformação do Paisagismo do Sistema) para o Sidecar do SAP HANA, conforme mostrado na figura anterior.
- Basicamente, o SLT é uma ferramenta capaz de realizar replicação de dados em tempo real.
- Depois que os dados são replicados no Banco de Dados SAP HANA com a ajuda do SLT, os relatórios que são executados no Banco de Dados Tradicional (Primário) podem ler os dados diretamente do Sidecar do Banco de Dados do SAP HANA, em vez de processá-los a partir do Banco de Dados Tradicional.
Como isso pode ser alcançado?
- Isso pode ser feito com a ajuda de uma conexão de Banco de Dados Secundário. (Consulte a Fig.1.0)
- A conexão do Banco de Dados Tradicional (Primário) ao Banco de Dados Secundário é estabelecida com a ajuda do código de transação: DBACOCKPIT onde é mantido o Nome da Conexão do Banco de Dados Secundário para estabelecer a conexão entre o Banco de Dados Primário e Secundário.
- Há uma pequena alteração nas consultas de seleção de relatórios para ler os dados e a alteração consiste em adicionar a palavra-chave CONEXÃO seguida pelo Nome da Conexão antes da variável alvo nas declarações de Open SQL.
Conclusão:
- Geralmente, os clientes optam por essa opção para testar o desempenho do SAP HANA como banco de dados, pois têm muito poucos relatórios/transações que estão causando problemas de desempenho com o Banco de Dados Tradicional (Primário) existente, mesmo após aplicar todos os tipos de técnicas de ajuste de desempenho para esses objetos afetados.
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
© 2025 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?