
Aprende en Comunidad
Avalados por :


Como enfrentar os desafios dos cientistas de dados com o SAP HANA: Um guia completo
- Creado 01/03/2024
- Modificado 01/03/2024
- 1 Vistas
0
Cargando...
Introdução
Este é o quarto de 5 posts de blog que fazem parte da série "SAP BTP Data & Analytics Showcase". Recomendo que consulte nosso post geral para uma melhor compreensão do cenário de ponta a ponta, envolvendo múltiplas soluções de banco de dados e análise SAP HANA na nuvem.
Hoje em dia, falamos muito sobre inteligência artificial, aprendizado de máquina, análise preditiva e ciência de dados tanto em nossa vida diária quanto nos negócios. Especialistas como cientistas de dados desempenham um papel essencial na implementação de casos de uso de dados e análises de valor agregado para as empresas. No entanto, os cientistas de dados ainda enfrentam alguns desafios que dificultam sua capacidade de trabalhar de forma eficaz e extrair valor comercial dos dados em ambientes do mundo real. Você pode conferir o post de blog de uma renomada especialista em ciência de dados da SAP para obter mais informações sob sua perspectiva.
Para demonstrar como nossas soluções unificadas de dados e análises SAP HANA abordam alguns desafios dos cientistas de dados e ajudam em seu trabalho diário de forma abrangente e flexível, me motiva a criar este post de blog.
Nas próximas seções deste blog, gostaria de destacar como os cientistas de dados podem escolher as soluções desejadas, combinar capacidades de nosso portfólio e resolver um problema específico de ponta a ponta:
- Preparação de dados - Para fechar a lacuna entre cientistas de dados e TI, recomendamos que os cientistas de dados possam se envolver desde cedo na fase de integração e preparação de dados. É oferecido um único local (SAP Data Warehouse Cloud) para combinar todos os dados necessários de diferentes fontes, em todo o panorama de TI real da empresa.
- Criação de modelos - O código aberto (por exemplo, Python ou R) é um pilar importante dos projetos de ciência de dados. Os cientistas de dados podem continuar usando scripts de Python no Jupyter Notebook, onde a conexão com os artefatos do SAP Data Warehouse Cloud foi estabelecida, e treinar modelos de ML.
- Inferência de modelos - Modelos de ML treinados são reutilizados para fazer uma previsão. Os resultados da previsão são facilmente escritos de volta ao SAP Data Warehouse Cloud (por meio de um esquema chamado Open SQL Schema), que pode então ser consumido para aprimorar seus modelos de dados.
- Visualização de resultados - Como última etapa, para mostrar descobertas/padrões por trás dos dados de forma consumível, por exemplo, para os usuários comerciais, é criado ou aprimorado um painel agradável que combina resultados preditivos por meio de ferramentas de autoatendimento no SAP Analytics Cloud.
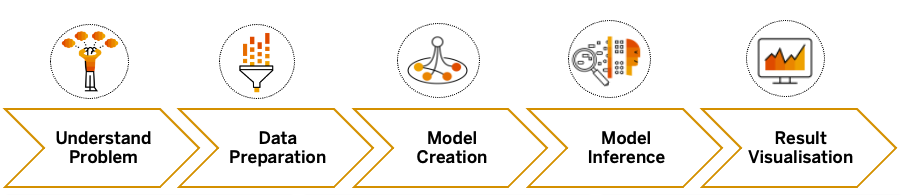
Figura 1: Cenário de Ciência de Dados de Ponta a Ponta
...
Pedro Pascal
Se unió el 07/03/2018
Facebook
Twitter
Pinterest
Telegram
Linkedin
Whatsapp
Sin respuestas
 No hay respuestas para mostrar
Se el primero en responder
No hay respuestas para mostrar
Se el primero en responder
contacto@primeinstitute.com
(+51) 1641 9379
(+57) 1489 6964
© 2024 Copyright. Todos los derechos reservados.
Desarrollado por Prime Institute
Hola ¿Puedo ayudarte?